Snapshots and Movies
Overview:
- Geometry-based Muscle Modeling for Facial Animation
(June 2001)
- Face to Face: From Real Humans to Realistic Facial
Animation (Oct 2001)
- Texturing Faces (May 2002)
- Automatic Generation of Subdivision Surface Head Models
from Point Cloud Data (May 2002)
- Automatic Generation of Non-Verbal Facial
Expressions from Speech (July 2002)
- Head shop: Generating animated head models
with anatomical structure (July 2002)
- "May I talk to you? :-)" - Facial
Animation from Text (October 2002)
- Reanimating the Dead: Reconstruction of Expressive Faces
from Skull Data (July 2003)
The video clips you find here document the progress of our facial modeling
and animation system. You may freely use the movies for research
and for demonstration purposes, as long as the source is properly
referenced. Commercial use is, of course, prohibited.
We have tried to provide a variety of file formats and quality
settings to enable playback on a wide range of machines with
different software. Compression ratios vary a lot between formats, and
some of the files are quite big, even when restricting to a minimum of
visual quality. Please be aware of this if you have a slow network
link, such as a modem.
This movie demonstrates the features of our geometry-based muscle modeling
tool (PDF paper):
 full movie (avi, 46.8 MB)
, for lower quality version (avi, 27.7 MB) click
here
full movie (avi, 46.8 MB)
, for lower quality version (avi, 27.7 MB) click
here
For previewing or slow connections, you might consider downloading the
movie in separate parts and/or lower quality:
All movie files are in AVI format with audio and a resolution of 256x256
pixels.
Here is a short description of what is demonstrated in each part (this
is pretty much a transcript of the speech track in the movie).
Part 1: Head model components
To create an animatable model from an individual face, we acquire its
geometry using a range scanner. Several photographs are taken from
different viewing angles. A textured triangle mesh is generated, in
the example shown with 3000 polygons. The model also includes a
skull. Skin regions are automatically attached to the fixed part of
the bone structure or to the rotating mandible. Several components
that cannot be obtained by scanning are modeled as separate
components, in particular eyes, teeth and tongue.
Our approach also handles synthetic data. As an example, we have
prepared a triangle mesh consisting of fourteen thousand polygons from
the Stanford dragon data set. It was created by cutting off the head
from the original triangle mesh and applying a mesh simplification
algorithm. The skull mesh was in this case created by computing an
offset surface and deleting those parts that don't correspond to bony
tissue. Since tongue and teeth are already in the model,
the only additional part is a pair of eyes.
Part 2: Interactive muscle editing
In our interactive edting tool, muscle outlines are simply sketched
onto the surface of the mesh. The actual muscle shape is then adapted
to the local geometry, so that the muscle follows the curvature of the
surface and will flow over the skull when contracted. Sphincter
muscles are created in a similar fashion, only an additional center of
contraction has to be specified. Muscle outlines can be re-edited in
several ways for fine-tuning muscle shape.
Part 3: Transferring muscles to another head model
Since manual creation of a complete set of facial muscles still takes
considerable time, we have devised a simple method to transfer an
existing muscle set from one head to another, if both of these share a
common skull model. In an interactive fitting procedure, the skull
model for a new head (the female shown in the clip) is placed into the
skin mesh and deformed using affine transformations. The
transformation from the skull of the original model to the skull of
the new model is now applied to the original muscle set. Note that
only the muscle outlines are transferred in this way, so
adaptation of the muscle shape to the local geometry of the new head
is performed as before. The resulting transferred muscle layout
usually still needs some editing - in the order of a few minutes - to
accomodate for individual traits in the new face, e.g. mouth shape.
Part 4: Animations of two human heads and the Stanford dragon
These animations have been produced by linear blending of muscle
contraction parameters (plus jaw and eyelid movement) between
expressions. A mass-spring system simulates skin deformation due to
muscle contraction and jaw rotation. All animations have been
recorded in real-time from a 1GHz Linux-PC. Since the muscle set for
the female head was transferred from the male head (as demonstrated in
part three), we can use exactly the same animation parameters to
reproduce animated expressions - without additional re-touching. While
this method obviously does not consider the many individual nuances of
facial expression, the expressions are of similar quality on both
models.
This movie demonstrates our facial animation system and shows some speech
synchronized facial animations (PDF paper).

Please choose the file format / codec that works best on your system.
All movies have audio and a framerate of 25 fps.
We present a number of techniques to facilitate the generation of textures
for facial modeling. In particular, we address the generation of facial skin
textures from uncalibrated input photographs as well as the creation of
individual textures for facial components such as eyes or teeth. Apart from
an initial feature point selection for the skin texturing, all our methods
work fully automatically without any user interaction. The resulting
textures show a high quality and are suitable for both photo-realistic and
real-time facial animation (PDF paper).
(PDF paper)
coming up soon...
The movie shows a speech synchronized facial animation. In the first part of
the movie, only mouth movements have been generated automatically from
the speech signal (see also Speech Synchronization for
Physics-based Facial Animation). The second part of the movie includes
additional non-verbal facial expressions that have been generated
automatically from the speech signal in accordance to the results from a
paralinguistic analysis (PDF paper).
Please choose the file format / codec that works best on your system. All
movies have audio and a resolution of 496x496 pixels at 25 fps. The preview
versions exhibit higher compression artifacts than the high quality movies.
This is a transcript of the spoken text that has been used to create the
animations:
Hello! I'm a talking head, and all my movements have been generated fully
automatically from the speech signal.
What could I tell you? - Oh yes, I'm a source of wisdom and I'll let you share
my knowledge:
How happy is the little stone,
that rambles in the road alone,
and never cares about careers,
and exigencies never fears.
I CAN ALSO SHOUT! Could you hear me?
Here, the focus is on deformation of an animatable, structured head
model. This is used for adaptation of a generic head template to range scan
data, and for simulation of growth and aging. The video explains the
head model structure and the creation of individual models via this
deformation technique (PDF paper).
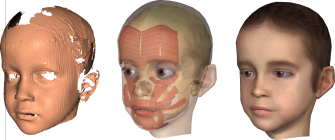
In this work, we combined a state-of-the-art text-to-speech (TtS) synthesis
component with our facial animation system. The TtS synthesis component
performs linguistic analysis of the text input and creates a speech signal
from phonetic and intonation information. The phonetic transcription is
additionally used to drive a speech synchronization method for the
physically based facial animation. Further high-level information from the
linguistic analysis such as different types of accents or pauses as well as
the type of the sentence is used to generate non-verbal speech-related
facial expressions such as movement of head, eyes, and eyebrows or voluntary
eye blinks (PDF paper).

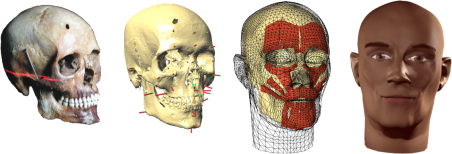
Facial reconstruction for postmortem identification of humans from
their skeletal remains is a challenging and fascinating part of
forensic art. The former look of a face can be approximated by
predicting and modeling the layers of tissue on the skull.
This work is as of today carried out solely by physical sculpting
with clay, where experienced artists invest up to hundreds of hours
to craft a reconstructed face model. Remarkably, one of the most
popular tissue reconstruction methods bears many resemblances with
surface fitting techniques used in computer graphics, thus
suggesting the possibility of a transfer of the manual approach to
the computer. In this paper, we present a facial reconstruction
approach that fits an anatomy-based virtual head model,
incorporating skin and muscles, to a scanned skull using
statistical data on skull / tissue relationships. The approach has
many advantages over the traditional process: a reconstruction can
be completed in about an hour from acquired skull data; also,
variations such as a slender or a more obese build of the modeled
individual are easily created. Last not least, by matching not only
skin geometry but also virtual muscle layers, an animatable head
model is generated that can be used to form facial expressions
beyond the neutral face typically used in physical
reconstructions (PDF paper).
[back]
[AG4]
[MPI homepage]