September 3 - September 7, 2007
Saarbrücken, Germany

|
|
8th Max-Planck Advanced
Course on the Foundations of Computer Science September 3 - September 7, 2007 Saarbrücken, Germany |
|
Slides used by prof. Simon and prof. Zomorodian, and solutions to some exercises. Look below at the abstracts of lectures.
There will be eight blocks of lectures, exercises and discussions, two per lecturer. Each block is about 4 hours. A morning or afternoon block will start with 1 1/2 hours of lecture, followed by 1 1/2 hours of exercises (in small groups) with coffee breaks, followed by a 1 hour discussion of the exercises. The only exception is the last block, in which the exercise session will be replaced by a panel discussion about challenges in the research areas of the lecturers. During the exercise periods, the respective lecturer will be around, as well as some fruit, snacks, and drinks.
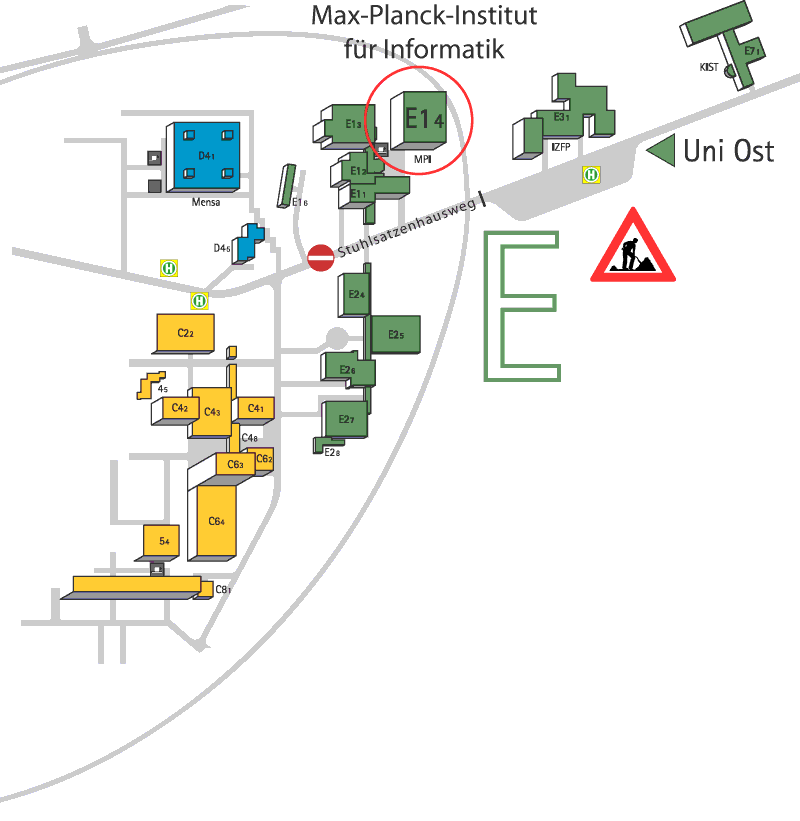
All lectures will take place in room HS001 ('Hoersaal 1') at the ground floor of the Computer Science builiding (Number E1.3 in the campus map) right next to the MPII building (Number E1.4). The exercise sessions and discussions will take place in room 024 at the ground floor of the MPII building.
| September 3 Monday |
September 4 Tuesday |
September 5 Wednesday |
September 6 Thursday |
September 7 Friday |
|||
|---|---|---|---|---|---|---|---|
| 9.00-13.00 | Cesa-Bianchi / Lugosi The Weighted Average Forecaster |
Zomorodian Topological Persistence |
Cesa-Bianchi / Lugosi Randomized Prediction and Applications |
Simon Stability of Clustering II |
|
||
| 13.00-14.30 | break |
break |
break |
break |
|||
| 14.30-18.30 | Zomorodian Concepts of Algebraic Topology |
Excursion | Simon Stability of Clustering I |
Cesa-Bianchi / Lugosi Prediction under Incomplete Feedback |
|||
| Evening | School Dinner |
Below you find short abstracts of the lectures. Clicking on the photos gets you to the respective lecturers' homepage.
Nicolò Cesa-BianchiUniversità degli Studi di Milano |

|
Learning, Prediction and Games
Unlike standard statistical approaches to forecasting, prediction of
individual sequences does not impose any probabilistic assumption on
the data-generating mechanism. Yet, prediction algorithms can be constructed
that work well for all possible sequences, in the sense that their
performance is always nearly as good as the best forecasting strategy in a
given reference class. In this course we will first introduce a general
model for sequential prediction and define some basic deterministic
and randomized prediction strategies for various loss functions. We
will then analyze their application to problems of prediction with
partial feedback and to repeated game playing, including multiarmed
bandit problems, calibration, and minimization of internal regret.
|
Gábor LugosiPompeu Fabra University |

|
|
Hans Ulrich SimonRuhr-Universität Bochum |

|
Stability of Clustering
The topic of the tutorial is "brand-new" so that we cannot provide pointers to textbooks dealing with stability of clustering. In order to get a general idea of cluster analysis, we recommend to follow (one or more of) the following suggestions:
Later (but before the tutorial), we will provide further material
about clustering stability that will be fairly self-contained (including
up-to-date pointers to the relevant literature and talk slides.)
|
Afra ZomorodianDartmouth College |

|
Topological Data Analysis
We often seek to understand the structure of a set of data points.
Generally, we assume that the points are sampled from some underlying
space in which we are interested.
One approach to data analysis is clustering, where we assume that the
underlying space had multiple components.
As such, clustering attempts to recover the way in which the original
space was connected -- its connectivity.
Topological data analysis -- the topic of my two lectures --
extends this analysis by examining other attributes of connectivity, such
as the existence of tunnels or enclosed spaces.
|
{kind=link}