
max planck institut
informatik
informatik

Organizers: H. Lensch, B. Rosenhahn, H.-P. Seidel, C. Theobalt, T. Thormählen, M. Wand
|
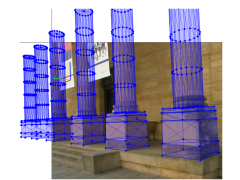
This course will provide a clear and in-depth tutorial on state-of-the-art techniques in the area of 3D scene analysis and synthesis from images or video. It will be given by renowned experts in the field and will cover both theoretical and practical aspects. The course language is English and the level of difficulty is well suited for research students or practitioners with basic knowledge about 3D geometry, image processing, and computer graphics. The tutorial is structured into five sessions with the following topics: Session 1: Camera motion estimation and 3D reconstruction (Thorsten Thormählen)Simultaneous estimation of camera motion and 3D reconstruction from image sequences is a well-established technique in computer vision. Often this problem is referred to as Structure-from-Motion (SfM), Structure-and-Motion (SaM), or Visual Simultaneous Location and Mapping (Visual SLAM). This session starts with an introduction to projective geometry and different mathematical camera models. Next, linear entities are presented that described the geometry of multiple views, e.g., the fundamental matrix or the trifocal tensor. Using these foundations, different approaches for camera motion estimation from images or video will be described. Furthermore, techniques for 3D reconstruction of the static 3D scene geometry are introduced. The session also covers extensions to the basic algorithms, e.g., how to handle multiple moving cameras that capture the same scene simultaneously or how to apply additional constraints. In the last part of this session, we discuss the robustness, accuracy, and computational effort of the proposed methods and how it can be improved. Session 2: Human motion capture (Bodo Rosenhahn)In this session we will give an introduction to human motion capture from image data. This includes human detection in images, segmentation, registration, 2D-3D pose fitting and human motion models. We will first teach important foundations needed for computing pose parameters from image data, like, the modeling and representation of kinematic chains, twists, the exponential mapping, the adjoint transform, modeling of geometric entities (points, lines, planes in space), and efficient numerical optimization of pose parameters. The tutorial contains a first part on all necessary geometric foundations. In the second part of this session we demonstrate the power of these models in several experiments and successful research projects. Session 3: Image-based appearance acquisition (Hendrik Lensch)Besides the shape, the texture and the reflection properties are important aspects of a scene that needs to be acquired for realistic reproduction. In this part of the tutorial we will categorize the set of image-based appearance acquisition methods which capture the dependence of a scenes appearance under varying illumination. The technique ranges from relatively simple approaches for static and opaque surfaces to more involved measurement techniques for arbitrary surfaces including those which exhibit subsurface scattering, refractions or interreflections. The captured data sets allow for photo-realistic re-renderings of the scene in arbitrary virtual illumination conditions. Session 4: Reconstruction techniques for shape and motion (Michael Wand)This part of the tutorial addresses the problem of reconstructing shape and motion from geometric data. At this point, we assume that we have obtained animated geometry from a real-time 3D sensor system such as realtime LIDAR, or space-time stereo measurement systems, or the similar. The question is now how to interpret the data. The main issues with such raw data are noise problems, incompleteness, and the lack of correspondence information. We will discuss techniques to reconstruct smooth geometry and filling in holes by integrating geometry information from all time steps. As a side product, we will obtain dense correspondences between all frames that can be used for applications such as simultaneous editing. The key component is a statistically motivated optimazation technique that separates structure (shape) and motion (time varying deformation fields) for partial geometric data. Session 5: Reconstructing Detailed Animation Models from Multi-view Video (Christian Theobalt)
Realistic animation of virtual humans is still a tremendous technical challenge.
All aspects of the virtual human have to be modeled at high accuracy since the unforgiving eye of the
observer will unmask even small inaccuracies instantaneously. Very important aspects
of a virtual character are convincing textural
surface appearance, but, most importantly, the overall geometry and the motion of body and attire.
To facilitate the animation of humans,
animators can resort to a repertoire of techniques that enables them to measure certain aspects
of a human in the real world. For instance, full-body scanners can be used to capture a detailed
static surface representation of the actor. Motion capture systems can be used to measure skeletal motion
parameters of a person. However, during motion recording the person usually has to wear skin-tight
clothing, and it is almost impossible to get detailed information on time-varying surface geometry.
In other words, the current capture technology provides a limited level of support, but
a tremendous amount of manual work is still needed to create the final character model
from different data sources. |
|
| Time: | September 8th, 2009, 9:00 - 16:00 | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Room: | Seminar room 113, Carl-Zeiss-Strasse 3 | ||||||||||||||||||||
| Materials: | Tutorial Notes | ||||||||||||||||||||
| Registration: |
DAGM 2009 Registration Site On-site registration will be offered from 8:30 - 9:00. | ||||||||||||||||||||
| Schedule: |
|