
max planck institut
informatik
informatik

 |
 |
 |
This seminar covers a variety of advanced topics in computer graphics relevant to current research. Each talk will be based on recent publications from leading international conferences and journals.
Schedule:
Date Topic 10.11.2005 HDR Displays 17.11.2005 Presentation Techniques 24.11.2005 Reconstructing Human Shape and Motion 1.12.2005 As-Rigid-As-Possible Shape Manipulation
Presentation Techniques8.12.2005 Qualitative Aspects of Character Motion
Rendering with Real World Lighting: Importance Sampling for Environment Maps15.12.2005 Lightcuts: A Scalable Approach to Illumination
Importance-Driven Volume Rendering22.12.2005 - 5.1.2006 Break: Merry Christmas and a Happy New Year! 12.1.2005 presentations:
- Lightcuts: A Scalable Approach to Illumination
- Rendering with Real World Lighting: Importance Sampling
19.1.2006 presentations:
- As-Rigid-As-Possible Shape Manipulation
- Reconstructing Human Shape and Motion
26.1.2006 presentations:
- Qualitative Aspects of Character Motion
- Importance-Driven Volume Rendering
Topics:
- Importance-Driven Volume Rendering
- Lightcuts: A Scalable Approach to Illumination
- Rendering with Real World Lighting: Importance Sampling for Environment Maps
- Reconstructing Human Shape and Motion
- Automatic Selection of "Best" Views of an Object
- Generalized barycentric coordinates and their applications
- TextureMontage: Seamless Texturing of Arbitrary Surfaces From Multiple Images
- As-Rigid-As-Possible Shape Manipulation
- Qualitative Aspects of Character Motion
- Physics-based Character Animation
- Compression Techniques for Precomputed Radiance Transfer
- Salient Geometric Features for Partial Shape Matching and Similarity
- Gradient Domain Methods for Tone Mapping and Image Processing
- Character Animation and Motion Capture Data
- Videorealistic Speech Animation
- Interactive Rendering of Complex 3D Models
- Visibility Culling for Time-Varying Volume Rendering Using Temporal Occlusion Coherence
Material:
Time and Place:
- Thu, 9-11 a.m.
- room 233 (rotunda on 2nd floor), building E1.4 (MPI)
Instructors:
Format:
- discussion of one paper per week
- all students must read the paper and prepare a 1/2 to 1 page summary
- block of presentations (1-2 full days) at end of semester
Grading policy:
- participation in class
- discussion with advisor (yes, you're allowed to ask questions ;-)
- final presentation in class (30 min talk, 15 min questions)
- written report on presented papers
Prerequisites:
- basic knowledge of Computer Graphics
Remarks:
- the seminar will be held in English
- possible followups: diploma, master, or bachelor thesis, FoPra, HiWi job
 |
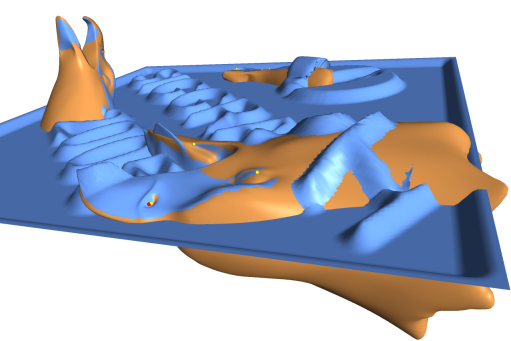
This paper introduces importance-driven volume rendering as a novel technique for automatic focus and context display of volumetric data. Our technique is a generalization of cut-away views, which ? depending on the viewpoint ? remove or suppress less important parts of a scene to reveal more important underlying information. We automatize and apply this idea to volumetric data. Each part of the volumetric data is assigned an object importance which encodes visibility priority. This property determines which structures should be readily discernible and which structures are less important. In those image regions, where an object occludes more important structures it is displayed more sparsely than in those areas where no occlusion occurs. Thus the objects of interest are clearly visible. For each object several representations, i.e., levels of sparseness, are specified. The display of an individual object may incorporate different levels of sparseness. The goal is to emphasize important structures and to maximize the information content in the final image. This paper also discusses several possible schemes for level of sparseness specification and different ways how object importance can be composited to determine the final appearance of a particular object.
References:
- Ivan Viola, Armin Kanitsar, Eduard Groller: Importance-Driven Volume Rendering. In Proceedings of the Conference on Visualization '04, 2004, pp.139-146.
Contact:
Presenter:
Date:
- discussion: 15.12.2005
- presentation: 26.1.2006
 |
Lightcuts is a scalable framework for computing realistic illumination. It handles arbitrary geometry, non-diffuse materials, and illumination from a wide variety of sources including point lights, area lights, HDR environment maps, sun/sky models, and indirect illumination. At its core is a new algorithm for accurately approximating illumination from many point lights with a strongly sublinear cost. We show how a group of lights can be cheaply approximated while bounding the maximum approximation error. A binary light tree and perceptual metric are then used to adaptively partition the lights into groups to control the error vs. cost tradeoff.
References:
- Bruce Walter, Sebastian Fernandez, Adam Arbree, Kavita Bala, Mike Donikian, Don Greenberg: Lightcuts: A Scalable Approach to Illumination". In Proceedings ACM SIGGRAPH '05, 2005, pp. 1098-1107.
- Alexander Keller: Instant Radiosity. In Proceedings ACM SIGGRAPH '97, 1997, pp. 49-56.
Contact:
Presenter:
Date:
- discussion: 15.12.2005
- presentation: 12.1.2006
 |
Real-world lighting is desirable in many engineering applications and improves the believability of virtual reality systems notoriously lacking realism in rendering. Real-world lighting is indispensable in many mixed reality applications in which virtual objects should be seamlessly merged with a real world scene. Traditionally, real-world lighting is captured into environment maps (EM), which represent distant illumination incoming to a point from thousands or even millions of directions that are distributed over a sphere. Many interactive rendering techniques can natively support shadows cast by point or directional light sources only. From a performance point of view it is thus desirable that captured environment maps are decomposed into a set of representative directional light sources. Several techniques based on the concept of importance sampling have been recently proposed to perform such a decomposition for static and dynamic lighting. The goal of the study is to get familiar with known techniques and compare their performance in terms of the computation speed, the quality of reproduced scene lighting, applicability for dynamic scenes, temporal coherence of resulting lighting, and other criteria.
References:
- General reading:
- Sameer Agarwal, Ravi Ramamoorthi, Serge Belongie, Henrik Vann Jensen: Structured importance sampling of environment maps. Proceedings of ACM SIGGRAPH 2003, pp. 605-612.
- Thomas Kollig, Alexander Keller: Efficient Illumination by High Dynamic Range Images. In Proceedings of Eurographics Symposium on Rendering '03, 2003, pp. 45-50.
- Additional reading for end-of-term presentation:
- Lian Wan, Tien-Tsin Wong, Chi-Sing Leung: Spherical Q2-tree for Sampling Dynamic Environment Sequences. In Proceedings of Eurographics Symposium on Rendering '05, 2005, pp. 21-30.
- Victor Ostromoukhov, Charles Donohue, Pierre-Marc Jodoin: Fast Hierarchical Importance Sampling with Blue Noise Properties. In Proceedings of ACM SIGGRAPH '04, 2004, pp. 488-495.
- Vlastimil Havran, Miloslaw Smyk, Grzegorz Krawczyk, Karol Myszkowski, Hans-Peter Seidel: Interactive System for Dynamic Scene Lighting using Caputred Video Environment Maps. In Proceedings of Eurographics Symposium on Rendering '05, 2005, pp. 31-42.
Contact:
Presenter:
Date:
- discussion: 8.12.2005
- presentation: 12.1.2006
 |
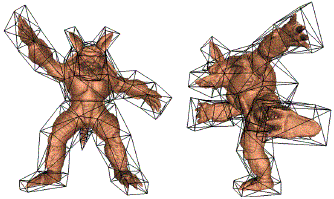
We introduce the SCAPE method (Shape Completion and Animation for People)---a data-driven method for building a human shape model that spans variation in both subject shape and pose. The method is based on a representation that incorporates both articulated and non-rigid deformations. We learn a pose deformation model that derives the non-rigid surface deformation as a function of the pose of the articulated skeleton. We also learn a separate model of variation based on body shape. Our two models can be combined to produce 3D surface models with realistic muscle deformation for different people in different poses, when neither appear in the training set. We show how the model can be used for shape completion --- generating a complete surface mesh given a limited set of markers specifying the target shape. We present applications of shape completion to partial view completion and motion capture animation. In particular, our method is capable of constructing a high-quality animated surface model of a moving person, with realistic muscle deformation, using just a single static scan and a marker motion capture sequence of the person.
References:
- Dragomir Anguelov, Praveen Srinivasan, Daphne Koller, Sebastian Thrun, Jim Rodgers, James Davis: SCAPE - Shape Completion and Animation of People. In Proceedings of ACM SIGGRAPH '05, 2005, pp. 408-416.
- Peter Sand, Leonard McMillan, and Jovan Popovic: Continuous Capture of Skin Deformation. In Proceedings of ACM SIGGRAPH '03, 2003, pp. 578-586.
- Edilson de Aguiar, Christian Theobalt, Marcus Magnor, Hans-Peter. Seidel: Reconstructing Human Shape and Motion from Multi-view Video. To appear in Proc. of CVMP 2005, London, UK, 2005.
Contact:
Presenter:
Date:
- discussion: 24.11.2005
- presentation: 19.1.2006
 |
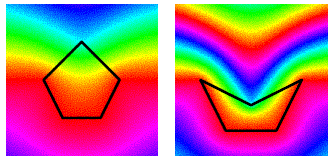
The project addresses the problem of automatic selection of "best" (most informative and perceptually salient) 2D views of a 3D object. It would be very useful for automatic generation of representative images for 3D models in a large shape repository.
References:
- Chang Ha Lee, Amitabh Varshney and David Jacobs, Mesh Saliency, ACM SIGGRAPH 2005.
- O. Polonsky, G. Patane, S. Biasotti, C. Gotsman, and M. Spagnuolo, What's in an Image: Towards the Computation of the "Best" View of an Object , The Visual Computer (Proc. of Pacific Graphics 2005), 2005.
- Farzin Mokhtarian, Automatic Selection of Optimal Views.
Contact:
Presenter:
- N.N.
Date:
- t.b.a.
 |
 |
Triangular barycentric coordinates are used to linearly interpolate values given at the vertices of a triangle and have numerous applications in computer graphics, geometric modeling, and computational mechanics. A proper extension of barycentric coordinates to polygons and polyhedra is currently a subject of intensive research. New barycentric coordinates for a polygon, the so-called mean value coordinates, were recently proposed in [1]. In [2] the mean value coordinates were generalized and used to generate free-form deformations of shapes approximated by triangular meshes.
References:
- M. S. Floater, Mean value coordinates, Comp. Aided Geom. Design 20 (2003), 19-27.
- T. Ju, S. Schaefer, and J. Warren, Mean Value Coordinates for Closed Triangular Meshes, ACM SIGGRAPH 2005.
Contact:
Presenter:
- N.N.
Date:
- t.b.a.
 |
This paper proposes a technique, called TextureMontage, to seamlessly map a patchwork of texture images onto an arbitrary 3D model. A texture atlas can be created through the specification of a set of correspondences between the model and any number of texture images. First, our technique automatically partitions the mesh and the images, driven solely by the choice of feature correspondences. Most charts will then be parameterized over their corresponding image planes through the minimization of a distortion metric based on both geometric distortion and texture mismatch across patch boundaries and images. Lastly, a surface texture inpainting technique is used to fill in the remaining charts of the surface with no corresponding texture patches. The resulting texture mapping satisfies the (sparse or dense) user-specified constraints while minimizing the distortion of the texture images and ensuring a smooth transition across the boundaries of different mesh patches.
References:
- Kun Zhou and Xi Wang and Yiying Tong and Mathieu Desbrun and Baining Guo and Heung-Yeung Shum, ``TextureMontage,'' ACM Trans. Graph., Vol. 24, No.3, 2005, pp. 1148-1155, http://doi.acm.org/10.1145/1073204.1073325 (from within MPI), http://research.microsoft.com/users/kunzhou/
Contact:
Presenter:
- N.N.
Date:
- t.b.a.
 |
This paper presents an interactive system that lets a user move and deform a two-dimensional shape without manually establishing a skeleton or freeform deformation (FFD) domain beforehand. The shape is represented by a triangle mesh and the user moves several vertices of the mesh as constrained handles. The system then computes the positions of the remaining free vertices by minimizing the distortion of each triangle. While physically based simulation or iterative refinement can also be used for this purpose, they tend to be slow. We present a two-step closed-form algorithm that achieves real-time interaction. The first step finds an appropriate rotation for each triangle and the second step adjusts its scale. The key idea is to use quadratic error metrics so that each minimization problem becomes a system of linear equations. After solving the simultaneous equations at the beginning of interaction, we can quickly find the positions of free vertices during interactive manipulation. Our approach successfully conveys a sense of rigidity of the shape, which is difficult in space-warp approaches. With a multiple-point input device, even beginners can easily move, rotate, and deform shapes at will.
References:
- General reading:
- Takeo Igarashi, Tomer Moscovich, John F. Hughes, As-Rigid-As-Possible Shape Manipulation, ACM Transactions on Computer Graphics, Vol.24, No.3, ACM SIGGRAPH 2005, Los Angels, USA, 2005.
- Additional reading for end-of-term presentation:
- upon agreement
Contact:
Presenter:
Date:
- discussion: 1.12.2005
- presentation: 19.1.2006
 |
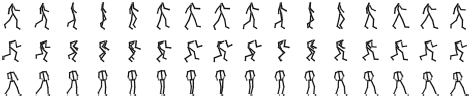
A recent focus of work in character animation has been on creating models of qualitative aspects of motion that relate to the mood, personality or role of the person completing the movements. This is sometimes referred to as movement .style., although that term may be a bit limiting. The general aim of this research has been to provide animators with higher level control over stylistic parameters of character motion. There have been three major approaches to this problem. One starts from motion capture data and uses statistical or machine learning approaches to build models of different aspects of motion. A second captures movements done in a range of ways and interpolates between them. The third makes use of the literature in psychology or the performing arts to understand which aspects of motion are important to model and then tries to build computational representations of these. Interesting projects could look at one of these classes of approaches or a comparison of two or three of them and the trade offs that result in each approach.
References:
- General reading:
- Pullen and Bregler: Texturing and Synthesis.
- Chi et al.: EMOTE. In Proceedings of ACM SIGGRAPH '00, 2000.
(optional)- Additional reading for end-of-term presentation:
- Style Machines
- Learning Physics-Based Motion Style with Nonlinear Inverse Optimization
- Sample interpolation: Verbs and Adverbs
- Approaches based on explicit representation
See for example:Contact:
Presenter(s):
Date:
- discussion: 8.12.2005
- presentation: 26.1.2006
 |
Applying physics-based simulation to character animation offers much potential. It can ensure that movements are physically accurate, automatically model subtle effects that are difficult to specify by hand, and allow characters to actually interact with their environment and other characters. Despite this potential, and nearly twenty years of work in the area, progress has been slow. The reasons for this include the subjective nature of character motion and the very difficult control problem - imagine trying to generate the correct forces to make a humanoid robot walk in a natural way and you will have some understanding of the complexity of the problem. Physics has been used in a variety of ways. One approach tries to build controllers that will generate the correct torque at character joints over time in order to create movement. See for example:
References:
- General reading:
- Jessica Hodgins et al.: Animating Human Athletics. In Proceedings of ACM SIGGRAPH '95, 1995.
- Additional reading for end-of-term presentation:
- http://www.cc.gatech.edu/gvu/animation/Areas/humanMotion/humanMotion.html
- http://www.cs.ucla.edu/~pfal/papers/siggraph2001.pdf
- Virtual stuntman
- doing it interactively
- One recent trend has been to model a subset of the physics involved to make the problem simpler:
Interesting projects could focus on one of these areas or examine other approaches to the application of physics to animation, such as space-time constraints.
Contact:
Presenter(s):
- N.N.
Date:
- t.b.a.
 |
Precomputed Radiance Transfer has emerged as a useful technique for the rendering of static objects in generalized distant-light situations. However, in order to provide interactive rendering speeds, the data needs to be compressed. In this session, different techniques and their trade-offs will be discussed.
References:
- General reading:
- Spherical Harmonic Lighting: The Gritty Details. Robin Green, Sony Computer Entertainment America, Game Developer Conference 2003.
- Additional reading for end-of-term presentation:
- Peter Pike Sloan, Jan Kautz, John Snyder: "Precomputed radiance transfer for real-time rendering in dynamic, low-frequency lighting environments", SIGGRAPH 2002.
- Peter-Pike Sloan, Jesse Hall, John Hart, and John Snyder: Clustered Principal Components for Precomputed Radiance Transfer, SIGGRAPH 2003.
- Ren Ng, Ravi Ramamoorthi, Pat Hanrahan: Triple Product Wavelet Integrals for All-Frequency Relighting, SIGGRAPH 2004.
It is possible to choose either the second or third paper only for in-depth discussion.
Contact:
Presenter:
- N.N.
Date:
- t.b.a.
 |
 |
 |
 |
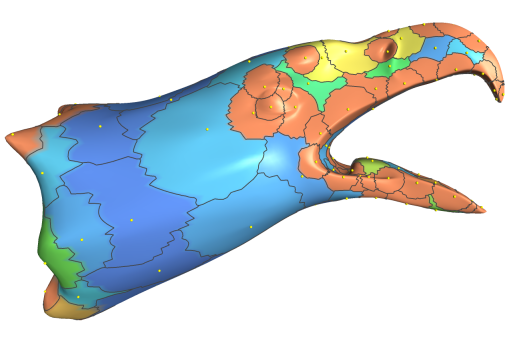
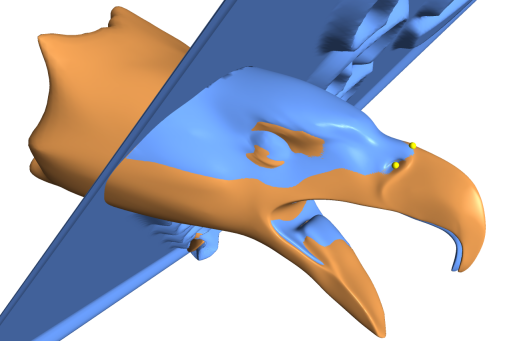
This paper introduces a method for partial matching of surfaces represented by triangular meshes. Our method matches surface regions that are numerically and topologically dissimilar, but approximate similar regions. We introduce novel local surface descriptors which efficiently represent the geometry of local regions of the surface. The descriptors are defined independently of the underlying triangulation, and form a compatible representation that allows matching of surfaces with different triangulations. To cope with the combinatorial complexity of partial matching of large meshes, we introduce the abstraction of salient geometric features and present a method to construct them. A salient geometric feature is a compound high-level feature of non-trivial local shapes. We show that a relatively small number of such salient geometric features characterizes the surface well for various similarity applications. Matching salient geometric features is based on indexing rotation-invariant features and a voting scheme accelerated by geometric hashing. We demonstrate the effectiveness of our method with a number of applications, such as computing self-similarity, alignments and sub-parts similarity.
References:
- Ran Gal and Daniel Cohen-Or, Salient Geometric Features for Partial Shape Matching and Similarity, Under revision for ACM TOG, 2005.
Contact:
Presenter:
- N.N.
Date:
- t.b.a.
 |
Gradient domain methods are powerful image processing tools, which found many practical applications ranging from the Photoshop's healing brush to complex video editing algorithms. Gradient domain methods operate on image gradients, which represent differences between neighboring pixels. The strengths of those methods partly comes from the fact that the gradient domain representation emphasizes local contrast, which is more important to the human visual perception than the actual pixel values. One of the most successful applications of the gradient domain methods is tone mapping, which aims at processing real-world high-dynamic range images in a such a way that they can be displayed on an ordinary monitors.
References:
- General reading:
- Raanan Fattal and Dani Lischinski and Michael Werman, Gradient domain high dynamic range compression, SIGGRAPH '02.
- Additional reading for end-of-term presentation:
- Iddo Drori, Tommer Leyvand, Shachar Fleishman, Daniel Cohen-Or, Hezy Yeshurun, Video Operations in the Gradient Domain, Technical Report, May 2004.
Contact:
Presenter:
- N.N.
Date:
- t.b.a.
 |
Style translation is the process of transforming an input motion into a new style while preserving its original content. This problem is motivated by the needs of interactive applications, which require rapid processing of captured performances. Our solution learns to translate by analyzing differences between performances of the same content in input and output styles. It relies on a novel correspondence algorithm to align motions, and a linear time-invariant model to represent stylistic differences. Once the model is estimated with system identification, our system is capable of translating streaming input with simple linear operations at each frame.
References:
- General reading:
- Eugene Hsu, Kari Pulli and Jovan Popovic: Style translation for human motion. In Proceedings ACM SIGGRAPH '05, 2005, pp.1082-1089.
- Additional reading for end-of-term presentation:
- Meinard Mueller, Roeder and Michael Clausen: Efficient content-based retrieval of motion capture data. In Proceedings ACM SIGGRAPH '05, 2005, pp. 677-685.
Contact:
Presenter:
- N.N.
Date:
- t.b.a.
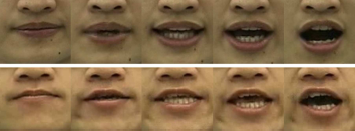 |
Traditional image-based videorealistic speech animation achieves significant visual realism at the cost of the collection of a large 5 to 10 minute video corpus from the specific person to be animated. This requirement hinders its use in broad applications, since a large video corpus for a specific person under a controlled recording setup may not be easily obtained. In this paper, a model transfer and adaptation algorithm is proposed which allows for a novel person to be animated using only a small video corpus. The algorithm starts with a multidimensional morphable model (MMM) previously trained from a different speaker with a large corpus, and transfers it to the novel speaker with a much smaller corpus. The algorithm consists of 1) a matching-by-synthesis algorithm which semi-automatically selects new MMM prototype images from the new video corpus and 2) a novel gradient descent linear regression algorithm which adapts the MMM phoneme models to the data in the novel video corpus. Encouraging experimental results are presented in which a morphable model trained from a performer with a 10-minute corpus is transferred to a novel person using a 15-second movie clip of him as the adaptation video corpus.
References:
- General reading:
- Tony Ezzat, Gadi Geiger, Tomaso Poggio: Trainable Videorealistic Speech Animation. In Proceedings ACM SIGGRAPH '02, 2002, pp.388-398.
- Additional reading for end-of-term presentation:
- Yao-Jen Chang, Tony Ezzat: Transferable Videorealistic Speech Animation. In Proceedings of the ACM SIGGRAPH/Eurographics Symposium on Computer Animation '05, 2005, pp.143-151.
- Yong Cao, Petros Faloutsos, Eddie Kohler, Frédéric Pighin: Real-time Speech Motion Synthesis from Recorded Motions. In Proceedings of the ACM SIGGRAPH/Eurographics Symposium on Computer Animation '04, 2004, pp.345-353.
<--->Contact:
Presenter:
- N.N.
Date:
- t.b.a.
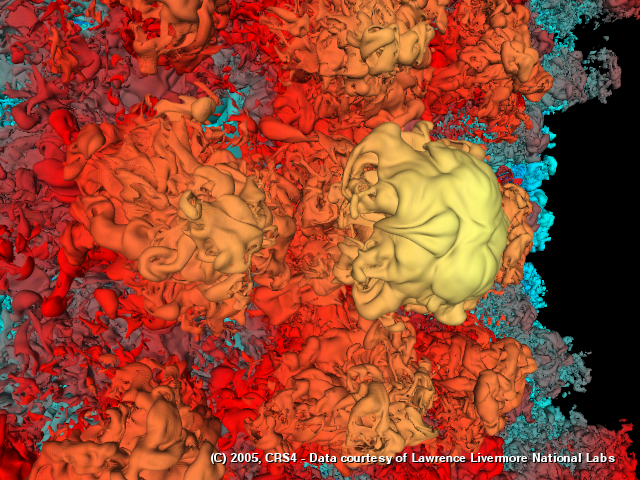 |
The paper presents an efficient approach for end-to-end out-of-core construction and interactive inspection of very large arbitrary surface models. The method tightly integrates visibility culling and out-of-core data management with a level-of-detail framework. At preprocessing time, the system generates a coarse volume hierarchy by binary space partitioning the input triangle soup. Leaf nodes partition the original data into chunks of a fixed maximum number of triangles, while inner nodes are discretized into a fixed number of cubical voxels. Each voxel contains a compact direction dependent approximation of the appearance of the associated volumetric subpart of the model when viewed from a distance. The approximation is constructed by a visibility aware algorithm that fits parametric shaders to samples obtained by casting rays against the full resolution dataset. At rendering time, the volumetric structure, maintained off-core, is refined and rendered in front-to-back order, exploiting vertex programs for GPU evaluation of view-dependent voxel representations, hardware occlusion queries for culling occluded subtrees, and asynchronous I/O for detecting and avoiding data access latencies. Since the granularity of the multiresolution structure is coarse, data management, traversal and occlusion culling cost is amortized over many graphics primitives. The efficiency and generality of the approach is demonstrated with the interactive rendering of extremely complex heterogeneous surface models on current commodity graphics platforms.
References:
- General reading:
- Enrico Gobbetti and Fabio Marton. Far Voxels - A Multiresolution Framework for Interactive Rendering of Huge Complex 3D Models on Commodity Graphics Platforms. ACM Transactions on Graphics, 24(3): 878-885, August 2005. Proc. SIGGRAPH 2005.
- Additional reading for end-of-term presentation:
- upon agreement
Contact:
Presenter:
- N.N.
Date:
- t.b.a.
 |
Typically there is a high coherence in data values between neighboring time steps in an iterative scientific software simulation; this characteristic similarly contributes to a corresponding coherence in the visibility of volume blocks when these consecutive time steps are rendered. Yet traditional visibility culling algorithms were mainly designed for static data, without consideration of such potential temporal coherency. In this paper, we explore the use of Temporal Occlusion Coherence (TOC) to accelerate visibility culling for time-varying volume rendering. In our algorithm, the opacity of volume blocks is encoded by means of Plenoptic Opacity Functions (POFs). A coherence-based block fusion technique is employed to coalesce time-coherent data blocks over a span of time steps into a single, representative block. Then POFs need only be computed for these representative blocks. To quickly determine the subvolumes that do not require updates in their visibility status for each subsequent time step, a hierarchical "TOC tree" data structure is constructed to store the spans of coherent time steps. To achieve maximal culling potential, while remaining conservative, we have extended our previous POF into an Optimized POF (OPOF) encoding scheme for this specific scenario. To test our general TOC and OPOF approach, we have designed a parallel time-varying volume rendering algorithm accelerated by visibility culling. Results from experimental runs on a 32-processor cluster confirm both the effectiveness and scalability of our approach.
References:
- General reading:
- Jinzhu Gao, Han-Wei Shen, Jian Huang and James Kohl, Visibility Culling for Time-Varying Volume Rendering Using Temporal Occlusion Coherence. Proc. of IEEE Visualization Conference, Austin, TX, October, 2004, pp. 147 - 154.
- Additional reading for end-of-term presentation:
- upon agreement
Contact:
Presenter:
- N.N.
Date:
- t.b.a.