
[ 1st Edition ] [ Free Newsletter ]
[ Seminars ] [ Seminars on CD ROM ] [ Consulting ]
One of the most compelling
features about Java is code reuse.
But to be revolutionary, you’ve got to be able to do a lot more than copy
code and change it.
That’s the approach used in
procedural languages like C, and it hasn’t worked very well. Like
everything in Java, the solution revolves around the class. You reuse code by
creating new classes, but instead of creating them from scratch, you use
existing classes that someone has already built and debugged.
The trick is to use the classes without
soiling the existing code. In this chapter you’ll see two ways to
accomplish this. The first is quite straightforward: You simply create objects
of your existing class inside the new class. This is called composition,
because the new class is composed of objects of existing
classes. You’re simply reusing the functionality of the code, not its
form.
The second approach is more subtle. It
creates a new class as a type of an existing class. You literally take
the form of the existing class and add code to it without modifying the existing
class. This magical act is called inheritance, and
the compiler does most of the work. Inheritance is one of the cornerstones of
object-oriented programming, and has additional implications that will be
explored in Chapter 7.
It turns out that much of the syntax and
behavior are similar for both composition and inheritance (which makes sense
because they are both ways of making new types from existing types). In this
chapter, you’ll learn about these code reuse
mechanisms.
Until now, composition has been used
quite frequently. You simply place object references inside new classes. For
example, suppose you’d like an object that holds several String
objects, a couple of primitives, and an object of another class. For the
nonprimitive objects, you put references inside your new class, but you define
the primitives directly:
//: c06:SprinklerSystem.java
// Composition for code reuse.
class WaterSource {
private String s;
WaterSource() {
System.out.println("WaterSource()");
s = new String("Constructed");
}
public String toString() { return s; }
}
public class SprinklerSystem {
private String valve1, valve2, valve3, valve4;
WaterSource source;
int i;
float f;
void print() {
System.out.println("valve1 = " + valve1);
System.out.println("valve2 = " + valve2);
System.out.println("valve3 = " + valve3);
System.out.println("valve4 = " + valve4);
System.out.println("i = " + i);
System.out.println("f = " + f);
System.out.println("source = " + source);
}
public static void main(String[] args) {
SprinklerSystem x = new SprinklerSystem();
x.print();
}
} ///:~One of the methods defined in
WaterSource is special: toString( ). You will learn later
that every nonprimitive object has a
toString( ) method,
and it’s called in special situations when the compiler wants a
String but it’s got one of these objects. So in the
expression:
System.out.println("source = " + source);the compiler sees you trying to add a
String object ("source = ") to a WaterSource. This
doesn’t make sense to it, because you can only “add” a
String to another String, so it says “I’ll turn
source into a String by calling toString( )!”
After doing this it can combine the two Strings and pass the resulting
String to System.out.println( ). Any time you want to allow
this behavior with a class you create you need only write a
toString( ) method.
At first glance, you might
assume—Java being as safe and careful as it is—that the compiler
would automatically construct objects for each of the references in the above
code; for example, calling the default constructor for WaterSource to
initialize source. The output of the print statement is in
fact:
valve1 = null valve2 = null valve3 = null valve4 = null i = 0 f = 0.0 source = null
Primitives that are fields in a class are
automatically initialized to zero,
as noted in Chapter 2. But the object references are initialized to null,
and if you try to call methods for any of them you’ll get an exception.
It’s actually pretty good (and useful) that you can still print them out
without throwing an exception.
It makes sense that the compiler
doesn’t just create a default object for every reference because that
would incur unnecessary overhead in many cases. If you want the references
initialized, you can do it:
All three approaches are shown
here:
//: c06:Bath.java
// Constructor initialization with composition.
class Soap {
private String s;
Soap() {
System.out.println("Soap()");
s = new String("Constructed");
}
public String toString() { return s; }
}
public class Bath {
private String
// Initializing at point of definition:
s1 = new String("Happy"),
s2 = "Happy",
s3, s4;
Soap castille;
int i;
float toy;
Bath() {
System.out.println("Inside Bath()");
s3 = new String("Joy");
i = 47;
toy = 3.14f;
castille = new Soap();
}
void print() {
// Delayed initialization:
if(s4 == null)
s4 = new String("Joy");
System.out.println("s1 = " + s1);
System.out.println("s2 = " + s2);
System.out.println("s3 = " + s3);
System.out.println("s4 = " + s4);
System.out.println("i = " + i);
System.out.println("toy = " + toy);
System.out.println("castille = " + castille);
}
public static void main(String[] args) {
Bath b = new Bath();
b.print();
}
} ///:~Note that in the Bath constructor
a statement is executed before any of the initializations take place. When you
don’t initialize at the point of definition, there’s still no
guarantee that you’ll perform any initialization before you send a message
to an object reference—except for the inevitable run-time
exception.
Here’s the output for the
program:
Inside Bath() Soap() s1 = Happy s2 = Happy s3 = Joy s4 = Joy i = 47 toy = 3.14 castille = Constructed
When print( ) is called it
fills in s4 so that all the fields are properly initialized by the time
they are
used.
Inheritance is an integral part of Java
(and OOP languages in general). It turns out that you’re always doing
inheritance when you create a class, because unless you explicitly inherit from
some other class, you implicitly inherit from Java’s
standard root class Object.
The syntax for composition is obvious,
but to perform inheritance there’s a distinctly different form. When you
inherit, you say “This new class is like that old class.” You state
this in code by giving the name of the class as usual, but before the opening
brace of the class body, put the keyword extends
followed by the name of the
base class. When you do
this, you automatically get all the data members and methods in the base class.
Here’s an example:
//: c06:Detergent.java
// Inheritance syntax & properties.
class Cleanser {
private String s = new String("Cleanser");
public void append(String a) { s += a; }
public void dilute() { append(" dilute()"); }
public void apply() { append(" apply()"); }
public void scrub() { append(" scrub()"); }
public void print() { System.out.println(s); }
public static void main(String[] args) {
Cleanser x = new Cleanser();
x.dilute(); x.apply(); x.scrub();
x.print();
}
}
public class Detergent extends Cleanser {
// Change a method:
public void scrub() {
append(" Detergent.scrub()");
super.scrub(); // Call base-class version
}
// Add methods to the interface:
public void foam() { append(" foam()"); }
// Test the new class:
public static void main(String[] args) {
Detergent x = new Detergent();
x.dilute();
x.apply();
x.scrub();
x.foam();
x.print();
System.out.println("Testing base class:");
Cleanser.main(args);
}
} ///:~This demonstrates a number of features.
First, in the Cleanser append( ) method, Strings are
concatenated to s using the += operator, which is one of the
operators (along with ‘+’) that the Java designers
“overloaded” to work with
Strings.
Second, both Cleanser and
Detergent contain a main( ) method.
You can create a main( ) for each one of your classes, and
it’s often recommended to code this way so that your test code is wrapped
in with the class. Even if you have a lot of classes in a program, only the
main( ) for the class invoked on the command line will be called.
(As long as main( ) is public, it doesn’t matter
whether the class that it’s part of is public.) So in this case,
when you say java Detergent, Detergent.main( ) will be
called. But you can also say java Cleanser to invoke
Cleanser.main( ), even though Cleanser is not a public
class. This technique of putting a main( ) in each class allows easy
unit testing for each class. And
you don’t need to remove the main( ) when you’re
finished testing; you can leave it in for later testing.
Here, you can see that
Detergent.main( ) calls Cleanser.main( ) explicitly,
passing it the same arguments from the command line (however, you could pass it
any String array).
It’s important that all of the
methods in Cleanser are public. Remember that if you leave off any
access specifier the member defaults to “friendly,” which allows
access only to package members. Thus, within this package, anyone could
use those methods if there were no access specifier. Detergent would have
no trouble, for example. However, if a class from some other package were to
inherit from Cleanser it could access only public members. So to
plan for inheritance, as a general rule make all fields private and all
methods public. (protected members also allow access by
derived classes; you’ll learn about this later.) Of course, in particular
cases you must make adjustments, but this is a useful
guideline.
Note that Cleanser has a set of
methods in its interface: append( ), dilute( ),
apply( ), scrub( ), and print( ). Because
Detergent is derived from Cleanser (via the
extends keyword) it automatically gets all these
methods in its interface, even though you don’t see them all explicitly
defined in Detergent. You can think of inheritance, then, as reusing
the interface. (The implementation comes along for free, but that part
isn’t the primary point.)
As seen in scrub( ),
it’s possible to take a method that’s been defined in the base class
and modify it. In this case, you might want to call the method from the base
class inside the new version. But inside scrub( ) you cannot simply
call scrub( ), since that would produce a recursive call, which
isn’t what you want. To solve this problem Java has the
keyword super that refers to the
“superclass” that the current class has been
inherited from. Thus the expression super.scrub( ) calls the
base-class version of the method scrub( ).
When inheriting you’re not
restricted to using the methods of the base class. You can also add new methods
to the derived class exactly the way you put any method in a class: just define
it. The method foam( ) is an example of this.
In Detergent.main( ) you can
see that for a Detergent object you can call all the methods that are
available in Cleanser as well as in Detergent (i.e.,
foam( )).
Since there are now two classes
involved—the base class and the
derived class—instead of
just one, it can be a bit confusing to try to imagine the resulting object
produced by a derived class. From the outside, it looks like the new class has
the same interface as the base class and maybe some additional methods and
fields. But inheritance doesn’t just copy the interface of the base class.
When you create an object of the derived class, it contains within it a
subobject of the base class. This
subobject is the same as if you
had created an object of the base class by itself. It’s just that, from
the outside, the subobject of the base class is wrapped within the derived-class
object.
Of course, it’s essential that the
base-class subobject be initialized correctly and there’s only one way to
guarantee that: perform the initialization in the constructor, by calling the
base-class constructor, which has all the appropriate knowledge and privileges
to perform the base-class initialization. Java automatically inserts calls to
the base-class constructor in the derived-class constructor. The following
example shows this working with three levels of inheritance:
//: c06:Cartoon.java
// Constructor calls during inheritance.
class Art {
Art() {
System.out.println("Art constructor");
}
}
class Drawing extends Art {
Drawing() {
System.out.println("Drawing constructor");
}
}
public class Cartoon extends Drawing {
Cartoon() {
System.out.println("Cartoon constructor");
}
public static void main(String[] args) {
Cartoon x = new Cartoon();
}
} ///:~The output for this program shows the
automatic calls:
Art constructor Drawing constructor Cartoon constructor
You can see that the construction happens
from the base “outward,” so the base class is initialized before the
derived-class constructors can access it.
Even if you don’t create a
constructor for Cartoon( ), the compiler will
synthesize a default constructor for you that calls the
base class constructor.
The above example has default
constructors; that is, they don’t have any
arguments. It’s easy for the compiler to call these because there’s
no question about what arguments to pass. If your class doesn’t have
default arguments, or if you want to call a base-class constructor that has an
argument, you must explicitly write the calls to the base-class constructor
using the super keyword and the appropriate
argument list:
//: c06:Chess.java
// Inheritance, constructors and arguments.
class Game {
Game(int i) {
System.out.println("Game constructor");
}
}
class BoardGame extends Game {
BoardGame(int i) {
super(i);
System.out.println("BoardGame constructor");
}
}
public class Chess extends BoardGame {
Chess() {
super(11);
System.out.println("Chess constructor");
}
public static void main(String[] args) {
Chess x = new Chess();
}
} ///:~If you don’t call the base-class
constructor in BoardGame( ), the compiler will complain that it
can’t find a constructor of the form Game( ). In addition, the
call to the base-class constructor must be the first thing you do in the
derived-class constructor. (The compiler will remind you if you get it
wrong.)
As just noted, the compiler forces you to
place the base-class constructor call first in the body of the derived-class
constructor. This means nothing else can appear before it. As you’ll see
in Chapter 10, this also prevents a derived-class constructor from catching any
exceptions that come from a base class. This can be inconvenient at
times.
It is very common to use composition and
inheritance together. The following example shows the creation of a more complex
class, using both inheritance and composition, along with the necessary
constructor
initialization:
//: c06:PlaceSetting.java
// Combining composition & inheritance.
class Plate {
Plate(int i) {
System.out.println("Plate constructor");
}
}
class DinnerPlate extends Plate {
DinnerPlate(int i) {
super(i);
System.out.println(
"DinnerPlate constructor");
}
}
class Utensil {
Utensil(int i) {
System.out.println("Utensil constructor");
}
}
class Spoon extends Utensil {
Spoon(int i) {
super(i);
System.out.println("Spoon constructor");
}
}
class Fork extends Utensil {
Fork(int i) {
super(i);
System.out.println("Fork constructor");
}
}
class Knife extends Utensil {
Knife(int i) {
super(i);
System.out.println("Knife constructor");
}
}
// A cultural way of doing something:
class Custom {
Custom(int i) {
System.out.println("Custom constructor");
}
}
public class PlaceSetting extends Custom {
Spoon sp;
Fork frk;
Knife kn;
DinnerPlate pl;
PlaceSetting(int i) {
super(i + 1);
sp = new Spoon(i + 2);
frk = new Fork(i + 3);
kn = new Knife(i + 4);
pl = new DinnerPlate(i + 5);
System.out.println(
"PlaceSetting constructor");
}
public static void main(String[] args) {
PlaceSetting x = new PlaceSetting(9);
}
} ///:~While the compiler forces you to
initialize the base classes, and requires that you do it right at the beginning
of the constructor, it doesn’t watch over you to make sure that you
initialize the member objects, so you must remember to pay attention to
that.
Java doesn’t have the C++ concept
of a destructor, a method that is automatically
called when an object is destroyed. The reason is probably that in Java the
practice is simply to forget about objects rather than to destroy them, allowing
the garbage collector to reclaim
the memory as necessary.
Often this is fine, but there are times
when your class might perform some activities during its lifetime that require
cleanup. As mentioned in Chapter 4, you can’t know when the garbage
collector will be called, or if it will be called. So if you want something
cleaned up for a class, you must explicitly write a special method to do it, and
make sure that the client programmer knows that they must call this method. On
top of this—as described in Chapter 10
(“Error Handling with Exceptions”)—you
must guard against an exception by putting such cleanup in a
finally clause.
Consider an example of a computer-aided
design system that draws pictures on the screen:
//: c06:CADSystem.java
// Ensuring proper cleanup.
import java.util.*;
class Shape {
Shape(int i) {
System.out.println("Shape constructor");
}
void cleanup() {
System.out.println("Shape cleanup");
}
}
class Circle extends Shape {
Circle(int i) {
super(i);
System.out.println("Drawing a Circle");
}
void cleanup() {
System.out.println("Erasing a Circle");
super.cleanup();
}
}
class Triangle extends Shape {
Triangle(int i) {
super(i);
System.out.println("Drawing a Triangle");
}
void cleanup() {
System.out.println("Erasing a Triangle");
super.cleanup();
}
}
class Line extends Shape {
private int start, end;
Line(int start, int end) {
super(start);
this.start = start;
this.end = end;
System.out.println("Drawing a Line: " +
start + ", " + end);
}
void cleanup() {
System.out.println("Erasing a Line: " +
start + ", " + end);
super.cleanup();
}
}
public class CADSystem extends Shape {
private Circle c;
private Triangle t;
private Line[] lines = new Line[10];
CADSystem(int i) {
super(i + 1);
for(int j = 0; j < 10; j++)
lines[j] = new Line(j, j*j);
c = new Circle(1);
t = new Triangle(1);
System.out.println("Combined constructor");
}
void cleanup() {
System.out.println("CADSystem.cleanup()");
// The order of cleanup is the reverse
// of the order of initialization
t.cleanup();
c.cleanup();
for(int i = lines.length; i >= 0; i--)
lines[i].cleanup();
super.cleanup();
}
public static void main(String[] args) {
CADSystem x = new CADSystem(47);
try {
// Code and exception handling...
} finally {
x.cleanup();
}
}
} ///:~Everything in this system is some kind of
Shape (which is itself a kind of Object since it’s
implicitly inherited from the root class). Each class redefines
Shape’s cleanup( ) method in addition to calling the
base-class version of that method using super. The specific Shape
classes—Circle, Triangle and Line—all have
constructors that “draw,” although any method called during the
lifetime of the object could be responsible for doing something that needs
cleanup. Each class has its own cleanup( ) method to restore
nonmemory things back to the way they were before the object
existed.
In main( ), you can see two
keywords that are new, and won’t officially be introduced until Chapter
10: try and finally.
The try keyword indicates that the block that follows (delimited by curly
braces) is a guarded region, which means that it is given special
treatment. One of these special treatments is that the code in the
finally clause following this guarded region is always executed,
no matter how the try block exits. (With exception handling, it’s
possible to leave a try block in a number of nonordinary ways.) Here, the
finally clause is saying “always call cleanup( ) for
x, no matter what happens.” These keywords will be explained
thoroughly in Chapter 10.
Note that in your cleanup method you must
also pay attention to the calling order for the base-class and member-object
cleanup methods in case one subobject depends on another. In general, you should
follow the same form that is imposed by a C++ compiler on its destructors: First
perform all of the cleanup work specific to your class, in the reverse order of
creation. (In general, this requires that base-class elements still be viable.)
Then call the base-class cleanup method, as demonstrated here.
There can be many cases in which the
cleanup issue is not a problem; you just let the garbage collector do the work.
But when you must do it explicitly, diligence and attention is
required.
There’s not much you can rely on
when it comes to garbage collection. The garbage
collector might never be called. If it is, it can reclaim objects in any order
it wants. It’s best to not rely on garbage collection for anything but
memory reclamation. If you want cleanup to take place, make your own cleanup
methods and don’t rely on finalize( ).
(As mentioned in Chapter 4, Java can be forced to call all the
finalizers.)
Only C++ programmers might be surprised
by name hiding, since it works differently in that language.
If
a Java base class has a method name that’s overloaded several times,
redefining that method name in the derived class will not hide any of the
base-class versions. Thus overloading works regardless of whether the method was
defined at this level or in a base class:
//: c06:Hide.java
// Overloading a base-class method name
// in a derived class does not hide the
// base-class versions.
class Homer {
char doh(char c) {
System.out.println("doh(char)");
return 'd';
}
float doh(float f) {
System.out.println("doh(float)");
return 1.0f;
}
}
class Milhouse {}
class Bart extends Homer {
void doh(Milhouse m) {}
}
class Hide {
public static void main(String[] args) {
Bart b = new Bart();
b.doh(1); // doh(float) used
b.doh('x');
b.doh(1.0f);
b.doh(new Milhouse());
}
} ///:~As you’ll see in the next chapter,
it’s far more common to override methods of the same name using exactly
the same signature and return type as in the base class. It can be confusing
otherwise (which is why C++ disallows it, to prevent you from making what is
probably a
mistake).
Both composition and inheritance allow
you to place subobjects inside your new class. You might
wonder about the difference between the two, and when to choose one over the
other.
Composition is generally used when you
want the features of an existing class inside your new class, but not its
interface. That is, you embed an object so that you can use it to implement
functionality in your new class, but the user of your new class sees the
interface you’ve defined for the new class rather than the interface from
the embedded object. For this effect, you embed private objects of
existing classes inside your new class.
Sometimes it makes sense to allow the
class user to directly access the composition of your new class; that is, to
make the member objects public. The member objects use implementation
hiding themselves, so this is a safe thing to do. When the user knows
you’re assembling a bunch of parts, it makes the interface easier to
understand. A car object is a good example:
//: c06:Car.java
// Composition with public objects.
class Engine {
public void start() {}
public void rev() {}
public void stop() {}
}
class Wheel {
public void inflate(int psi) {}
}
class Window {
public void rollup() {}
public void rolldown() {}
}
class Door {
public Window window = new Window();
public void open() {}
public void close() {}
}
public class Car {
public Engine engine = new Engine();
public Wheel[] wheel = new Wheel[4];
public Door left = new Door(),
right = new Door(); // 2-door
public Car() {
for(int i = 0; i < 4; i++)
wheel[i] = new Wheel();
}
public static void main(String[] args) {
Car car = new Car();
car.left.window.rollup();
car.wheel[0].inflate(72);
}
} ///:~Because the composition of a car is part
of the analysis of the problem (and not simply part of the underlying design),
making the members public assists the client programmer’s
understanding of how to use the class and requires less code complexity for the
creator of the class. However, keep in mind that this is a special case and that
in general you should make fields private.
When
you inherit, you take an existing class and make a special version of it. In
general, this means that you’re taking a general-purpose class and
specializing it for a particular need. With a little thought, you’ll see
that it would make no sense to compose a car using a vehicle object—a car
doesn’t contain a vehicle, it is a vehicle. The
is-a relationship is expressed with inheritance,
and the has-a relationship is expressed with
composition.
Now that you’ve been introduced to
inheritance, the keyword protected finally has
meaning. In an ideal world, private members would always be hard-and-fast
private, but in real projects there are times when you want to make
something hidden from the world at large and yet allow access for members of
derived classes. The protected keyword is a nod to pragmatism. It says
“This is private as far as the class user is concerned, but
available to anyone who inherits from this class or anyone else in the same
package.” That is,
protected in Java is
automatically “friendly.”
The best tack to take is to leave the
data members private—you should always
preserve your right to change the underlying implementation. You can then allow
controlled access to inheritors of your class through
protected methods:
//: c06:Orc.java
// The protected keyword.
import java.util.*;
class Villain {
private int i;
protected int read() { return i; }
protected void set(int ii) { i = ii; }
public Villain(int ii) { i = ii; }
public int value(int m) { return m*i; }
}
public class Orc extends Villain {
private int j;
public Orc(int jj) { super(jj); j = jj; }
public void change(int x) { set(x); }
} ///:~One of the advantages of inheritance is
that it supports incremental
development by allowing you to
introduce new code without causing bugs in existing code. This also isolates new
bugs inside the new code. By inheriting from an existing, functional class and
adding data members and methods (and redefining existing methods), you leave the
existing code—that someone else might still be using—untouched and
unbugged. If a bug happens, you know that it’s in your new code, which is
much shorter and easier to read than if you had modified the body of existing
code.
It’s rather amazing how cleanly the
classes are separated. You don’t even need the source code for the methods
in order to reuse the code. At most, you just import a package. (This is true
for both inheritance and composition.)
It’s important to realize that
program development is an incremental process, just like human learning. You can
do as much analysis as you want, but you still won’t know all the answers
when you set out on a project. You’ll have much more success—and
more immediate feedback—if you start out to “grow” your
project as an organic, evolutionary creature, rather than constructing it all at
once like a glass-box skyscraper.
Although inheritance for experimentation
can be a useful technique, at some point after things stabilize you need to take
a new look at your class hierarchy with an eye to collapsing it into a sensible
structure. Remember that underneath it all, inheritance is meant to express a
relationship that says “This new class is a type of that old
class.” Your program should not be concerned with pushing bits around, but
instead with creating and manipulating objects of various types to express a
model in the terms that come from the problem
space.
The most important aspect of inheritance
is not that it provides methods for the new class. It’s the relationship
expressed between the new class and the base class. This
relationship can be summarized by saying “The new
class is a type of the existing class.”
This description is not just a fanciful
way of explaining inheritance—it’s supported directly by the
language. As an example, consider a base class called Instrument that
represents musical instruments, and a derived class called Wind. Because
inheritance means that all of the methods in the base class are also available
in the derived class, any message you can send to the base class can also be
sent to the derived class. If the Instrument class has a
play( ) method, so will Wind instruments. This means we can
accurately say that a Wind object is also a type of Instrument.
The following example shows how the compiler supports this
notion:
//: c06:Wind.java
// Inheritance & upcasting.
import java.util.*;
class Instrument {
public void play() {}
static void tune(Instrument i) {
// ...
i.play();
}
}
// Wind objects are instruments
// because they have the same interface:
class Wind extends Instrument {
public static void main(String[] args) {
Wind flute = new Wind();
Instrument.tune(flute); // Upcasting
}
} ///:~What’s interesting in this example
is the tune( ) method, which accepts an Instrument reference.
However, in Wind.main( ) the tune( ) method is
called by giving it a Wind reference. Given that Java is particular about
type checking, it seems strange that a method that accepts one type will readily
accept another type, until you realize that a Wind object is also an
Instrument object, and there’s no method that tune( )
could call for an Instrument that isn’t also in Wind. Inside
tune( ), the code works for Instrument and anything derived
from Instrument, and the act of converting a Wind reference into
an Instrument reference is called
upcasting.
The reason for the term is historical,
and based on the way class inheritance diagrams
have
traditionally been drawn: with the root at the top of the page, growing
downward. (Of course, you can draw your diagrams any way you find helpful.) The
inheritance diagram for Wind.java is then:
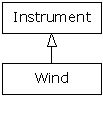
Casting from derived to base moves
up on the inheritance diagram, so it’s commonly referred to as
upcasting. Upcasting is always safe because you’re going from a
more specific type to a more general type. That is, the derived class is a
superset of the base class. It might contain more methods than the base class,
but it must contain at least the methods in the base class. The only
thing that can occur to the class interface during the upcast is that it can
lose methods, not gain them. This is why the compiler allows upcasting without
any explicit casts or other special notation.
You can also perform the reverse of
upcasting, called downcasting, but this involves a
dilemma that is the subject of Chapter
12.
In object-oriented programming, the most
likely way that you’ll create and use code is by simply packaging data and
methods together into a class, and using objects of that class. You’ll
also use existing classes to build new classes with composition. Less
frequently, you’ll use inheritance. So although inheritance gets a lot of
emphasis while learning OOP, it doesn’t mean that you should use it
everywhere you possibly can. On the contrary, you should use it sparingly, only
when it’s clear that inheritance is useful.
One of the clearest ways to
determine whether you should use composition or inheritance is to ask whether
you’ll ever need to upcast from your new class to the base class. If you
must upcast, then inheritance is necessary, but if you don’t need to
upcast, then you should look closely at whether you need inheritance. The next
chapter (polymorphism) provides one of the most compelling reasons for
upcasting, but if you remember to ask “Do I need to upcast?”
you’ll have a good tool for deciding between composition and
inheritance.
Java’s
final keyword has slightly different meanings
depending on the context, but in general it says “This cannot be
changed.” You might want to prevent changes for two reasons: design or
efficiency. Because these two reasons are quite different, it’s possible
to misuse the final keyword.
The following sections discuss the three
places where final can be used: for data, methods, and
classes.
Many programming languages have a way to
tell the compiler that a piece of data is “constant.” A constant is
useful for two reasons:
In the case of a
compile-time constant, the compiler is allowed to “fold” the
constant value into any
calculations in which it’s used; that is, the calculation can be performed
at compile-time, eliminating some run-time overhead. In Java, these sorts of
constants must be primitives and are expressed using the
final keyword. A value must be given at the time of definition of such a
constant.
When using
final
with object references rather than primitives the meaning gets a bit confusing.
With a primitive, final makes the value a constant, but with an
object reference, final makes the reference a constant. Once the
reference is initialized to an object, it can never be changed to point to
another object. However, the object itself can be modified; Java does not
provide a way to make any arbitrary object a constant. (You can, however, write
your class so that objects have the effect of being constant.) This restriction
includes arrays, which are also objects.
Here’s an example that demonstrates
final fields:
//: c06:FinalData.java
// The effect of final on fields.
class Value {
int i = 1;
}
public class FinalData {
// Can be compile-time constants
final int i1 = 9;
static final int VAL_TWO = 99;
// Typical public constant:
public static final int VAL_THREE = 39;
// Cannot be compile-time constants:
final int i4 = (int)(Math.random()*20);
static final int i5 = (int)(Math.random()*20);
Value v1 = new Value();
final Value v2 = new Value();
static final Value v3 = new Value();
// Arrays:
final int[] a = { 1, 2, 3, 4, 5, 6 };
public void print(String id) {
System.out.println(
id + ": " + "i4 = " + i4 +
", i5 = " + i5);
}
public static void main(String[] args) {
FinalData fd1 = new FinalData();
//! fd1.i1++; // Error: can't change value
fd1.v2.i++; // Object isn't constant!
fd1.v1 = new Value(); // OK -- not final
for(int i = 0; i < fd1.a.length; i++)
fd1.a[i]++; // Object isn't constant!
//! fd1.v2 = new Value(); // Error: Can't
//! fd1.v3 = new Value(); // change reference
//! fd1.a = new int[3];
fd1.print("fd1");
System.out.println("Creating new FinalData");
FinalData fd2 = new FinalData();
fd1.print("fd1");
fd2.print("fd2");
}
} ///:~Since i1 and VAL_TWO are
final primitives with compile-time values, they can both be used as
compile-time constants and are not different in any important way.
VAL_THREE is the more typical way you’ll see such constants
defined: public so they’re usable outside the package,
static to emphasize that there’s only one, and final to say
that it’s a constant. Note that
final
static primitives with constant initial values (that is, compile-time
constants) are named with all capitals by convention, with words separated by
underscores (This is just like C constants, which is where the convention
originated.) Also note that i5 cannot be known at compile-time, so it is
not capitalized.
Just because something is final
doesn’t mean that its value is known at compile-time. This is demonstrated
by initializing i4 and i5 at run-time using randomly generated
numbers. This portion of the example also shows the difference between making a
final value static or non-static. This difference shows up
only when the values are initialized at run-time, since the compile-time values
are treated the same by the compiler. (And presumably optimized out of
existence.) The difference is shown in the output from one run:
fd1: i4 = 15, i5 = 9 Creating new FinalData fd1: i4 = 15, i5 = 9 fd2: i4 = 10, i5 = 9
Note that the values of i4 for
fd1 and fd2 are unique, but the value for i5 is not changed
by creating the second FinalData object. That’s because it’s
static and is initialized once upon loading and not each time a new
object is created.
The variables v1 through v4
demonstrate the meaning of a final reference. As you can see in
main( ), just because v2 is final doesn’t mean
that you can’t change its value. However, you cannot rebind v2 to a
new object, precisely because it’s final. That’s what
final means for a reference. You can also see the same meaning holds true
for an array, which is just another kind of reference. (There is no way that I
know of to make the array references themselves final.) Making references
final seems less useful than making primitives
final.
Java allows the creation of
blank finals, which are
fields that are declared as final but are not given an initialization
value. In all cases, the blank final must be initialized before it is
used, and the compiler ensures this. However, blank finals provide much more
flexibility in the use of the final keyword since, for example, a
final field inside a class can now be different for each object and yet
it retains its immutable quality. Here’s an example:
//: c06:BlankFinal.java
// "Blank" final data members.
class Poppet { }
class BlankFinal {
final int i = 0; // Initialized final
final int j; // Blank final
final Poppet p; // Blank final reference
// Blank finals MUST be initialized
// in the constructor:
BlankFinal() {
j = 1; // Initialize blank final
p = new Poppet();
}
BlankFinal(int x) {
j = x; // Initialize blank final
p = new Poppet();
}
public static void main(String[] args) {
BlankFinal bf = new BlankFinal();
}
} ///:~You’re forced to perform
assignments to finals either with an expression at the point of
definition of the field or in every constructor. This way it’s guaranteed
that the final field is always initialized before use.
Java allows you to make
arguments final by
declaring them as such in the argument list. This means that inside the method
you cannot change what the argument reference points to:
//: c06:FinalArguments.java
// Using "final" with method arguments.
class Gizmo {
public void spin() {}
}
public class FinalArguments {
void with(final Gizmo g) {
//! g = new Gizmo(); // Illegal -- g is final
g.spin();
}
void without(Gizmo g) {
g = new Gizmo(); // OK -- g not final
g.spin();
}
// void f(final int i) { i++; } // Can't change
// You can only read from a final primitive:
int g(final int i) { return i + 1; }
public static void main(String[] args) {
FinalArguments bf = new FinalArguments();
bf.without(null);
bf.with(null);
}
} ///:~Note that you can still assign a
null reference to an argument that’s final without the compiler
catching it, just like you can with a non-final
argument.
The methods f( ) and
g( ) show what happens when primitive arguments are final:
you can read the argument, but you can't change
it.
There are two reasons for
final methods. The first is
to put a “lock” on the method to prevent any inheriting class from
changing its meaning. This is done for design reasons when you want to make sure
that a method’s behavior is retained during inheritance and cannot be
overridden.
The second reason for final
methods is efficiency. If you make a method final, you are allowing the
compiler to turn any calls to that method into
inline calls. When the
compiler sees a final method call it can (at its discretion) skip the
normal approach of inserting code to perform the method call mechanism (push
arguments on the stack, hop over to the method code and execute it, hop back and
clean off the stack arguments, and deal with the return value) and instead
replace the method call with a copy of the actual code in the method body. This
eliminates the overhead of the method call. Of course, if a method is big, then
your code begins to bloat and you probably won’t see any performance gains
from inlining, since any improvements will be dwarfed by the amount of time
spent inside the method. It is implied that the Java compiler is able to detect
these situations and choose wisely whether to inline a final method.
However, it’s better to not trust that the compiler is able to do this and
make a method final only if it’s quite small or if you want to
explicitly prevent overriding.
Any private methods in a class are
implicitly final. Because you can’t access a private method,
you can’t override it (even though the compiler doesn’t give an
error message if you try to override it, you haven’t overridden the
method, you’ve just created a new method). You can add the final
specifier to a private method but it doesn’t give that method any
extra meaning.
This issue can cause confusion, because
if you try to override a private method (which is implicitly
final) it seems to work:
//: c06:FinalOverridingIllusion.java
// It only looks like you can override
// a private or private final method.
class WithFinals {
// Identical to "private" alone:
private final void f() {
System.out.println("WithFinals.f()");
}
// Also automatically "final":
private void g() {
System.out.println("WithFinals.g()");
}
}
class OverridingPrivate extends WithFinals {
private final void f() {
System.out.println("OverridingPrivate.f()");
}
private void g() {
System.out.println("OverridingPrivate.g()");
}
}
class OverridingPrivate2
extends OverridingPrivate {
public final void f() {
System.out.println("OverridingPrivate2.f()");
}
public void g() {
System.out.println("OverridingPrivate2.g()");
}
}
public class FinalOverridingIllusion {
public static void main(String[] args) {
OverridingPrivate2 op2 =
new OverridingPrivate2();
op2.f();
op2.g();
// You can upcast:
OverridingPrivate op = op2;
// But you can't call the methods:
//! op.f();
//! op.g();
// Same here:
WithFinals wf = op2;
//! wf.f();
//! wf.g();
}
} ///:~“Overriding” can only occur
if something is part of the base-class interface. That is, you must be able to
upcast an object to its base type and call the same method (the point of this
will become clear in the next chapter). If a method is private, it
isn’t part of the base-class interface. It is just some code that’s
hidden away inside the class, and it just happens to have that name, but if you
create a public, protected or “friendly” method in the
derived class, there’s no connection to the method that might happen to
have that name in the base class. Since a private method is unreachable
and effectively invisible, it doesn’t factor into anything except for the
code organization of the class for which it was
defined.
When you say that an entire class is
final (by preceding its definition with the final keyword), you
state that you don’t want to inherit from this class or allow anyone else
to do so. In other words, for some reason the design of your class is such that
there is never a need to make any changes, or for safety or security reasons you
don’t want subclassing. Alternatively, you might be dealing with an
efficiency issue, and you want to make sure that any activity involved with
objects of this class are as efficient as possible.
//: c06:Jurassic.java
// Making an entire class final.
class SmallBrain {}
final class Dinosaur {
int i = 7;
int j = 1;
SmallBrain x = new SmallBrain();
void f() {}
}
//! class Further extends Dinosaur {}
// error: Cannot extend final class 'Dinosaur'
public class Jurassic {
public static void main(String[] args) {
Dinosaur n = new Dinosaur();
n.f();
n.i = 40;
n.j++;
}
} ///:~Note that the data members can be
final or not, as you choose. The same rules apply to final for
data members regardless of whether the class is defined as final.
Defining the class as final simply prevents inheritance—nothing
more. However, because it prevents inheritance all
methods in a final class are implicitly final, since there’s
no way to override them. So the compiler has the same efficiency options as it
does if you explicitly declare a method final.
It can seem to be sensible to make a
method final while you’re designing a class. You might feel that
efficiency
is very important when using your class and that no one could possibly want to
override your methods anyway. Sometimes this is true.
But be careful with your assumptions. In
general, it’s difficult to anticipate how a class can be reused,
especially a general-purpose class. If you define a method as final you
might prevent the possibility of reusing your class through inheritance in some
other programmer’s project simply because you couldn’t imagine it
being used that way.
The standard Java library is a good
example of this. In particular, the Java 1.0/1.1 Vector class was
commonly used and might have been even more useful if, in the name of
efficiency, all the methods hadn’t been made final. It’s
easily conceivable that you might want to inherit and override with such a
fundamentally useful class, but the designers somehow decided this wasn’t
appropriate. This is ironic for two reasons. First, Stack is inherited
from Vector, which says that a Stack is a Vector,
which isn’t really true from a logical standpoint. Second, many of the
most important methods of Vector, such as addElement( ) and
elementAt( ) are synchronized. As you will see in Chapter 14,
this incurs a significant performance overhead that probably wipes out any gains
provided by final. This lends credence to the theory that programmers are
consistently bad at guessing where optimizations should occur. It’s just
too bad that such a clumsy design made it into the standard library where we
must all cope with it. (Fortunately, the Java 2 container library replaces
Vector with ArrayList, which behaves much more civilly.
Unfortunately, there’s still plenty of new code being written that uses
the old container library.)
It’s also interesting to note that
Hashtable, another important standard library class, does not have
any final methods. As mentioned elsewhere in this book, it’s quite
obvious that some classes were designed by completely different people than
others. (You’ll see that the method names in Hashtable are much
briefer compared to those in Vector, another piece of evidence.) This is
precisely the sort of thing that should not be obvious to consumers of a
class library. When things are inconsistent it just makes more work for the
user. Yet another paean to the value of design and code walkthroughs. (Note that
the Java 2 container library replaces Hashtable with
HashMap.)
In more traditional languages, programs
are loaded all at once as part of the startup process. This is followed by
initialization, and then the program begins. The process of initialization in
these languages must be carefully controlled so that the order of initialization
of statics doesn’t cause trouble. C++, for example, has problems if
one static expects another static to be valid before the second
one has been initialized.
Java doesn’t have this problem
because it takes a different approach to loading. Because everything in Java is
an object, many activities become easier, and this is one of them. As you will
learn more fully in the next chapter, the compiled code for each class exists in
its own separate file. That file isn’t loaded until the code is needed. In
general, you can say that “Class code is loaded at the point of first
use.” This is often not until the first object of that class is
constructed, but loading also occurs when a static field or static
method is accessed.
The point of first use is also where the
static initialization takes place. All the static objects and the
static code block will be initialized in textual
order (that is, the order that you write them down in the
class definition) at the point of loading. The statics, of course, are
initialized only
once.
It’s helpful to look at the whole
initialization process, including
inheritance, to get a full picture of what happens. Consider the following
code:
//: c06:Beetle.java
// The full process of initialization.
class Insect {
int i = 9;
int j;
Insect() {
prt("i = " + i + ", j = " + j);
j = 39;
}
static int x1 =
prt("static Insect.x1 initialized");
static int prt(String s) {
System.out.println(s);
return 47;
}
}
public class Beetle extends Insect {
int k = prt("Beetle.k initialized");
Beetle() {
prt("k = " + k);
prt("j = " + j);
}
static int x2 =
prt("static Beetle.x2 initialized");
public static void main(String[] args) {
prt("Beetle constructor");
Beetle b = new Beetle();
}
} ///:~The output for this program
is:
static Insect.x1 initialized static Beetle.x2 initialized Beetle constructor i = 9, j = 0 Beetle.k initialized k = 47 j = 39
The first thing that happens when you run
Java on Beetle is that you try to access Beetle.main( ) (a
static method), so the loader goes out and finds the compiled code for
the Beetle class (this
happens to be in a file called Beetle.class). In the process of loading
it, the loader notices that it has a base class (that’s what the
extends keyword says), which it then loads. This will happen whether or
not you’re going to make an object of that base class. (Try commenting out
the object creation to prove it to yourself.)
If the base class has a base class, that
second base class would then be loaded, and so on. Next, the
static initialization in
the root base class (in this case, Insect) is performed, and then the
next derived class, and so on. This is important because the derived-class
static initialization might depend on the base class member being initialized
properly.
At this point, the necessary classes have
all been loaded so the object can be created. First, all the primitives in this
object are set to their default values and the object references are set to
null—this happens in one fell swoop by setting the memory in the
object to binary zero. Then the base-class constructor will be called. In
this case the call is automatic, but you can also specify the base-class
constructor call (as the first operation in the Beetle( )
constructor) using super. The base class construction goes through the
same process in the same order as the derived-class constructor. After the
base-class constructor completes, the instance variables are initialized in
textual order. Finally, the rest of the body of the constructor is
executed.
Both inheritance and composition allow
you to create a new type from existing types. Typically, however, you use
composition to reuse existing types as part of the underlying implementation of
the new type, and inheritance when you want to reuse the interface. Since the
derived class has the base-class interface, it can be upcast to the base,
which is critical for polymorphism, as you’ll see in the next chapter.
Despite the strong emphasis on
inheritance in object-oriented programming, when you start a design you should
generally prefer composition during the first cut and use inheritance only when
it is clearly necessary. Composition tends to be more flexible. In addition, by
using the added artifice of inheritance with your member type, you can change
the exact type, and thus the behavior, of those member objects at run-time.
Therefore, you can change the behavior of the composed object at
run-time.
Although code reuse through composition
and inheritance is helpful for rapid project development, you’ll generally
want to redesign your class hierarchy before allowing
other programmers to become dependent on it. Your goal is a hierarchy in which
each class has a specific use and is neither too big (encompassing so much
functionality that it’s unwieldy to reuse) nor annoyingly small (you
can’t use it by itself or without adding
functionality).