
Technical Details
MINERVA assumes an architecture of a P2P Web search federation as follows. Each peer is fully autonomous and has its own local search engine and has a local index that can be built from the peer's own crawls or imported from external sources and tailored to the user's thematic interest profile. The index contains inverted index lists
for each term holding
Peers may share their local indexes (or specific fragments of local indexes) by posting meta-information into a P2P network. This meta-information contains compact statistics and quality-of-service information, and effectively forms a conceptually global directory.
A peer uses the global directory to identify candidate peers that are most likely able to provide good query results. A query posed by a user can first be executed on the user's own peer, but can be additionally forwarded to these peers for better result quality. The results obtained from there are merged by the query initiator.
The rationale for an appropriate query routing strategy, i.e., the selection of the most promising peers among the, possibly large, set of candidates, is based on the following three observations:
- The query initiator should prefer peers that are likely to hold highly relevant information for a particular query.
- On the other hand, the query should be forwarded to peers that offer a great deal of \textit{complementary results}.
- Finally, this process should incur acceptable overhead.
MINERVA is a fully operational distributed search engine that we have implemented and that serves as a valuable testbed for our work.
A conceptually global but physically distributed directory, which is layered on top of a Chord-style Dynamic Hash Table (DHT), holds compact, aggregated information about the peers' local indexes and only to the extent that the individual peers are willing to disclose. We use the DHT to partition the term space, such that every peer is responsible for the metadata of a randomized subset of terms within the global directory. We do not distribute index lists across the directory. For failure resilience and availability, the responsibility for a term may be shared and replicated across multiple peers.
Directory maintenance, query routing, and query processing work as follows. In a preliminary step (step 0), every peer publishes statistical information (Posts) about every term in its local index to the directory. A hash function is applied to the term in order to determine the peer currently responsible for this term. This peer maintains a PeerList of all postings for this term from peers across the network. Posts contain contact information about the peer who posted this summary together with statistics to calculate IR-style relevance measures for a term (e.g., the size of the inverted list for the term, the maximum average score among the term's inverted list entries, or some other statistical measure). The query initiator retrieves the PeerLists for all query terms from the distributed directory. It then combines the given information to find the most promising peers for the current query. For efficiency reasons, the query initiator can decide to not retrieve the complete PeerLists (could be a problem if there are thousands of peers in the system) but only a subset, say the top-k peers from each list, or more appropriately the top-k peers over all lists, calculated by a distributed top-k algorithm.
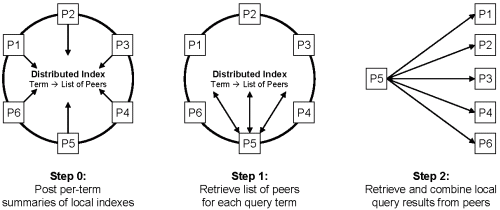
Metadata Dissemination, Query Routing, and Query Processing in MINERVA
The goal in the query routing process is to select promising peers for a query based on the previously published per-term statistics (Posts). We want to complete the entire selection process before sending the query to the remote peers so that all remote peers can be queried in parallel to avoid additional latencies. In other words, we do not rely on the actual query results of a peer when selecting subsequent peers, but only on its previously published statistics.