Release 2 (9.2)
Part Number A96624-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| PL/SQL User's Guide and Reference Release 2 (9.2) Part Number A96624-01 |
|
Civilization advances by extending the number of important operations that we can perform without thinking about them. --Alfred North Whitehead
This chapter shows you how to use subprograms, which let you name and encapsulate a sequence of statements. Subprograms aid application development by isolating operations. They are like building blocks, which you can use to construct modular, maintainable applications.
This chapter discusses the following topics:
Subprograms are named PL/SQL blocks that can take parameters and be invoked. PL/SQL has two types of subprograms called procedures and functions. Generally, you use a procedure to perform an action and a function to compute a value.
Like unnamed or anonymous PL/SQL blocks, subprograms have a declarative part, an executable part, and an optional exception-handling part. The declarative part contains declarations of types, cursors, constants, variables, exceptions, and nested subprograms. These items are local and cease to exist when you exit the subprogram. The executable part contains statements that assign values, control execution, and manipulate Oracle data. The exception-handling part contains exception handlers, which deal with exceptions raised during execution.
Consider the following procedure named debit_account, which debits a bank account:
PROCEDURE debit_account (acct_id INTEGER, amount REAL) IS old_balance REAL; new_balance REAL; overdrawn EXCEPTION; BEGIN SELECT bal INTO old_balance FROM accts WHERE acct_no = acct_id; new_balance := old_balance - amount; IF new_balance < 0 THEN RAISE overdrawn; ELSE UPDATE accts SET bal = new_balance WHERE acct_no = acct_id; END IF; EXCEPTION WHEN overdrawn THEN ... END debit_account;
When invoked or called, this procedure accepts an account number and a debit amount. It uses the account number to select the account balance from the accts database table. Then, it uses the debit amount to compute a new balance. If the new balance is less than zero, an exception is raised; otherwise, the bank account is updated.
Subprograms provide extensibility; that is, they let you tailor the PL/SQL language to suit your needs. For example, if you need a procedure that creates new departments, you can easily write one, as follows:
PROCEDURE create_dept (new_dname VARCHAR2, new_loc VARCHAR2) IS BEGIN INSERT INTO dept VALUES (deptno_seq.NEXTVAL, new_dname, new_loc); END create_dept;
Subprograms also provide modularity; that is, they let you break a program down into manageable, well-defined modules. This supports top-down design and the stepwise refinement approach to problem solving.
In addition, subprograms promote reusability and maintainability. Once validated, a subprogram can be used with confidence in any number of applications. If its definition changes, only the subprogram is affected. This simplifies maintenance.
Finally, subprograms aid abstraction, the mental process of deriving a universal from particulars. To use subprograms, you must know what they do, not how they work. Therefore, you can design applications from the top down without worrying about implementation details. Dummy subprograms (stubs) allow you to defer the definition of procedures and functions until you test and debug the main program.
A procedure is a subprogram that performs a specific action. You write procedures using the syntax:
[CREATE [OR REPLACE]] PROCEDURE procedure_name[(parameter[, parameter]...)] [AUTHID {DEFINER | CURRENT_USER}] {IS | AS} [PRAGMA AUTONOMOUS_TRANSACTION;] [local declarations] BEGIN executable statements [EXCEPTION exception handlers] END [name];
where parameter stands for the following syntax:
parameter_name [IN | OUT [NOCOPY] | IN OUT [NOCOPY]] datatype [{:= | DEFAULT} expression]
The CREATE clause lets you create standalone procedures, which are stored in an Oracle database. You can execute the CREATE PROCEDURE statement interactively from SQL*Plus or from a program using native dynamic SQL (see Chapter 11).
The AUTHID clause determines whether a stored procedure executes with the privileges of its owner (the default) or current user and whether its unqualified references to schema objects are resolved in the schema of the owner or current user. You can override the default behavior by specifying CURRENT_USER. For more information, see "Invoker Rights Versus Definer Rights".
The pragma AUTONOMOUS_TRANSACTION instructs the PL/SQL compiler to mark a procedure as autonomous (independent). Autonomous transactions let you suspend the main transaction, do SQL operations, commit or roll back those operations, then resume the main transaction. For more information, see "Doing Independent Units of Work with Autonomous Transactions".
You cannot constrain the datatype of a parameter. For example, the following declaration of acct_id is illegal because the datatype CHAR is size-constrained:
PROCEDURE reconcile (acct_id CHAR(5)) IS ... -- illegal
However, you can use the following workaround to size-constrain parameter types indirectly:
DECLARE SUBTYPE Char5 IS CHAR(5); PROCEDURE reconcile (acct_id Char5) IS ...
A procedure has two parts: the specification (spec for short) and the body. The procedure spec begins with the keyword PROCEDURE and ends with the procedure name or a parameter list. Parameter declarations are optional. Procedures that take no parameters are written without parentheses.
The procedure body begins with the keyword IS (or AS) and ends with the keyword END followed by an optional procedure name. The procedure body has three parts: a declarative part, an executable part, and an optional exception-handling part.
The declarative part contains local declarations, which are placed between the keywords IS and BEGIN. The keyword DECLARE, which introduces declarations in an anonymous PL/SQL block, is not used. The executable part contains statements, which are placed between the keywords BEGIN and EXCEPTION (or END). At least one statement must appear in the executable part of a procedure. The NULL statement meets this requirement. The exception-handling part contains exception handlers, which are placed between the keywords EXCEPTION and END.
Consider the procedure raise_salary, which increases the salary of an employee by a given amount:
PROCEDURE raise_salary (emp_id INTEGER, amount REAL) IS current_salary REAL; salary_missing EXCEPTION; BEGIN SELECT sal INTO current_salary FROM emp WHERE empno = emp_id; IF current_salary IS NULL THEN RAISE salary_missing; ELSE UPDATE emp SET sal = sal + amount WHERE empno = emp_id; END IF; EXCEPTION WHEN NO_DATA_FOUND THEN INSERT INTO emp_audit VALUES (emp_id, 'No such number'); WHEN salary_missing THEN INSERT INTO emp_audit VALUES (emp_id, 'Salary is null'); END raise_salary;
When called, this procedure accepts an employee number and a salary increase amount. It uses the employee number to select the current salary from the emp database table. If the employee number is not found or if the current salary is null, an exception is raised. Otherwise, the salary is updated.
A procedure is called as a PL/SQL statement. For example, you might call the procedure raise_salary as follows:
raise_salary(emp_id, amount);
A function is a subprogram that computes a value. Functions and procedures are structured alike, except that functions have a RETURN clause. You write (local) functions using the syntax:
[CREATE [OR REPLACE ] ] FUNCTION function_name [ ( parameter [ , parameter ]... ) ] RETURN datatype [ AUTHID { DEFINER | CURRENT_USER } ] [ PARALLEL_ENABLE [ { [CLUSTER parameter BY (column_name [, column_name ]... ) ] | [ORDER parameter BY (column_name [ , column_name ]... ) ] } ] [ ( PARTITION parameter BY { [ {RANGE | HASH } (column_name [, column_name]...)] | ANY } ) ] ] [DETERMINISTIC] [ PIPELINED [ USING implementation_type ] ] [ AGGREGATE [UPDATE VALUE] [WITH EXTERNAL CONTEXT] USING implementation_type ] {IS | AS} [ PRAGMA AUTONOMOUS_TRANSACTION; ] [ local declarations ] BEGIN executable statements [ EXCEPTION exception handlers ] END [ name ];
The CREATE clause lets you create standalone functions, which are stored in an Oracle database. You can execute the CREATE FUNCTION statement interactively from SQL*Plus or from a program using native dynamic SQL.
The AUTHID clause determines whether a stored function executes with the privileges of its owner (the default) or current user and whether its unqualified references to schema objects are resolved in the schema of the owner or current user. You can override the default behavior by specifying CURRENT_USER.
The PARALLEL_ENABLE option declares that a stored function can be used safely in the slave sessions of parallel DML evaluations. The state of a main (logon) session is never shared with slave sessions. Each slave session has its own state, which is initialized when the session begins. The function result should not depend on the state of session (static) variables. Otherwise, results might vary across sessions.
The hint DETERMINISTIC helps the optimizer avoid redundant function calls. If a stored function was called previously with the same arguments, the optimizer can elect to use the previous result. The function result should not depend on the state of session variables or schema objects. Otherwise, results might vary across calls. Only DETERMINISTIC functions can be called from a function-based index or a materialized view that has query-rewrite enabled. For more information, see Oracle9i SQL Reference.
The pragma AUTONOMOUS_TRANSACTION instructs the PL/SQL compiler to mark a function as autonomous (independent). Autonomous transactions let you suspend the main transaction, do SQL operations, commit or roll back those operations, then resume the main transaction.
You cannot constrain (with NOT NULL for example) the datatype of a parameter or a function return value. However, you can use a workaround to size-constrain them indirectly. See "Understanding PL/SQL Procedures".
Like a procedure, a function has two parts: the spec and the body. The function spec begins with the keyword FUNCTION and ends with the RETURN clause, which specifies the datatype of the return value. Parameter declarations are optional. Functions that take no parameters are written without parentheses.
The function body begins with the keyword IS (or AS) and ends with the keyword END followed by an optional function name. The function body has three parts: a declarative part, an executable part, and an optional exception-handling part.
The declarative part contains local declarations, which are placed between the keywords IS and BEGIN. The keyword DECLARE is not used. The executable part contains statements, which are placed between the keywords BEGIN and EXCEPTION (or END). One or more RETURN statements must appear in the executable part of a function. The exception-handling part contains exception handlers, which are placed between the keywords EXCEPTION and END.
Consider the function sal_ok, which determines if a salary is out of range:
FUNCTION sal_ok (salary REAL, title VARCHAR2) RETURN BOOLEAN IS min_sal REAL; max_sal REAL; BEGIN SELECT losal, hisal INTO min_sal, max_sal FROM sals WHERE job = title; RETURN (salary >= min_sal) AND (salary <= max_sal); END sal_ok;
When called, this function accepts an employee salary and job title. It uses the job title to select range limits from the sals database table. The function identifier, sal_ok, is set to a Boolean value by the RETURN statement. If the salary is out of range, sal_ok is set to FALSE; otherwise, sal_ok is set to TRUE.
A function is called as part of an expression, as the example below shows. The function identifier sal_ok acts like a variable whose value depends on the parameters passed to it.
IF sal_ok(new_sal, new_title) THEN ...
The RETURN statement immediately completes the execution of a subprogram and returns control to the caller. Execution then resumes with the statement following the subprogram call. (Do not confuse the RETURN statement with the RETURN clause in a function spec, which specifies the datatype of the return value.)
A subprogram can contain several RETURN statements. The last lexical statement does not need to be a RETURN statement. Executing any RETURN statement completes the subprogram immediately. However, to have multiple exit points in a subprogram is a poor programming practice.
In procedures, a RETURN statement cannot return a value, and therefore cannot contain an expression. The statement simply returns control to the caller before the normal end of the procedure is reached.
However, in functions, a RETURN statement must contain an expression, which is evaluated when the RETURN statement is executed. The resulting value is assigned to the function identifier, which acts like a variable of the type specified in the RETURN clause. Observe how the function balance returns the balance of a specified bank account:
FUNCTION balance (acct_id INTEGER) RETURN REAL IS acct_bal REAL; BEGIN SELECT bal INTO acct_bal FROM accts WHERE acct_no = acct_id; RETURN acct_bal; END balance;
The following example shows that the expression in a function RETURN statement can be arbitrarily complex:
FUNCTION compound ( years NUMBER, amount NUMBER, rate NUMBER) RETURN NUMBER IS BEGIN RETURN amount * POWER((rate / 100) + 1, years); END compound;
In a function, there must be at least one execution path that leads to a RETURN statement. Otherwise, you get a function returned without value error at run time.
To be callable from SQL statements, a stored function must obey the following "purity" rules, which are meant to control side effects:
SELECT statement or a parallelized INSERT, UPDATE, or DELETE statement, the function cannot modify any database tables.INSERT, UPDATE, or DELETE statement, the function cannot query or modify any database tables modified by that statement.SELECT, INSERT, UPDATE, or DELETE statement, the function cannot execute SQL transaction control statements (such as COMMIT), session control statements (such as SET ROLE), or system control statements (such as ALTER SYSTEM). Also, it cannot execute DDL statements (such as CREATE) because they are followed by an automatic commit.If any SQL statement inside the function body violates a rule, you get an error at run time (when the statement is parsed).
To check for violations of the rules, you can use the pragma (compiler directive) RESTRICT_REFERENCES. The pragma asserts that a function does not read and/or write database tables and/or package variables. For example, the following pragma asserts that packaged function credit_ok writes no database state (WNDS) and reads no package state (RNPS):
CREATE PACKAGE loans AS ... FUNCTION credit_ok RETURN BOOLEAN; PRAGMA RESTRICT_REFERENCES (credit_ok, WNDS, RNPS); END loans;
Note: A static INSERT, UPDATE, or DELETE statement always violates WNDS. It also violates RNDS (reads no database state) if it reads any columns. A dynamic INSERT, UPDATE, or DELETE statement always violates WNDS and RNDS.
For more information about the purity rules and pragma RESTRICT_REFERENCES, see Oracle9i Application Developer's Guide - Fundamentals.
You can declare subprograms in any PL/SQL block, subprogram, or package. But, you must declare subprograms at the end of a declarative section after all other program items.
PL/SQL requires that you declare an identifier before using it. Therefore, you must declare a subprogram before calling it. For example, the following declaration of procedure award_bonus is illegal because award_bonus calls procedure calc_rating, which is not yet declared when the call is made:
DECLARE ... PROCEDURE award_bonus IS BEGIN calc_rating(...); -- undeclared identifier ... END; PROCEDURE calc_rating (...) IS BEGIN ... END;
In this case, you can solve the problem easily by placing procedure calc_rating before procedure award_bonus. However, the easy solution does not always work. For example, suppose the procedures are mutually recursive (call each other) or you want to define them in logical or alphabetical order.
You can solve the problem by using a special subprogram declaration called a forward declaration, which consists of a subprogram spec terminated by a semicolon. In the following example, the forward declaration advises PL/SQL that the body of procedure calc_rating can be found later in the block.
DECLARE PROCEDURE calc_rating ( ... ); -- forward declaration ...
Although the formal parameter list appears in the forward declaration, it must also appear in the subprogram body. You can place the subprogram body anywhere after the forward declaration, but they must appear in the same program unit.
You can group logically related subprograms in a package, which is stored in the database. That way, the subprograms can be shared by many applications. The subprogram specs go in the package spec, and the subprogram bodies go in the package body, where they are invisible to applications. Thus, packages allow you to hide implementation details. An example follows:
CREATE PACKAGE emp_actions AS -- package spec PROCEDURE hire_employee (emp_id INTEGER, name VARCHAR2, ...); PROCEDURE fire_employee (emp_id INTEGER); PROCEDURE raise_salary (emp_id INTEGER, amount REAL); ... END emp_actions; CREATE PACKAGE BODY emp_actions AS -- package body PROCEDURE hire_employee (emp_id INTEGER, name VARCHAR2, ...) IS BEGIN ... INSERT INTO emp VALUES (emp_id, name, ...); END hire_employee; PROCEDURE fire_employee (emp_id INTEGER) IS BEGIN DELETE FROM emp WHERE empno = emp_id; END fire_employee; PROCEDURE raise_salary (emp_id INTEGER, amount REAL) IS BEGIN UPDATE emp SET sal = sal + amount WHERE empno = emp_id; END raise_salary; ... END emp_actions;
You can define subprograms in a package body without declaring their specs in the package spec. However, such subprograms can be called only from inside the package. For more information about packages, see Chapter 9.
Subprograms pass information using parameters. The variables or expressions referenced in the parameter list of a subprogram call are actual parameters. For example, the following procedure call lists two actual parameters named emp_num and amount:
raise_salary(emp_num, amount);
The next procedure call shows that expressions can be used as actual parameters:
raise_salary(emp_num, merit + cola);
The variables declared in a subprogram spec and referenced in the subprogram body are formal parameters. For example, the following procedure declares two formal parameters named emp_id and amount:
PROCEDURE raise_salary (emp_id INTEGER, amount REAL) IS BEGIN UPDATE emp SET sal = sal + amount WHERE empno = emp_id; END raise_salary;
A good programming practice is to use different names for actual and formal parameters.
When you call procedure raise_salary, the actual parameters are evaluated and the results are assigned to the corresponding formal parameters. If necessary, before assigning the value of an actual parameter to a formal parameter, PL/SQL converts the datatype of the value. For example, the following call to raise_salary is valid:
raise_salary(emp_num, '2500');
The actual parameter and its corresponding formal parameter must have compatible datatypes. For instance, PL/SQL cannot convert between the DATE and REAL datatypes. Also, the result must be convertible to the new datatype. The following procedure call raises the predefined exception VALUE_ERROR because PL/SQL cannot convert the second actual parameter to a number:
raise_salary(emp_num, '$2500'); -- note the dollar sign
When calling a subprogram, you can write the actual parameters using either positional or named notation. That is, you can indicate the association between an actual and formal parameter by position or name. So, given the declarations
DECLARE acct INTEGER; amt REAL; PROCEDURE credit_acct (acct_no INTEGER, amount REAL) IS ...
you can call the procedure credit_acct in four logically equivalent ways:
BEGIN credit_acct(acct, amt); -- positional notation credit_acct(amount => amt, acct_no => acct); -- named notation credit_acct(acct_no => acct, amount => amt); -- named notation credit_acct(acct, amount => amt); -- mixed notation
The first procedure call uses positional notation. The PL/SQL compiler associates the first actual parameter, acct, with the first formal parameter, acct_no. And, the compiler associates the second actual parameter, amt, with the second formal parameter, amount.
The second procedure call uses named notation. An arrow (=>) serves as the association operator, which associates the formal parameter to the left of the arrow with the actual parameter to the right of the arrow.
The third procedure call also uses named notation and shows that you can list the parameter pairs in any order. So, you need not know the order in which the formal parameters are listed.
The fourth procedure call shows that you can mix positional and named notation. In this case, the first parameter uses positional notation, and the second parameter uses named notation. Positional notation must precede named notation. The reverse is not allowed. For example, the following procedure call is illegal:
credit_acct(acct_no => acct, amt); -- illegal
You use parameter modes to define the behavior of formal parameters. The three parameter modes, IN (the default), OUT, and IN OUT, can be used with any subprogram. However, avoid using the OUT and IN OUT modes with functions. The purpose of a function is to take zero or more arguments (actual parameters) and return a single value. To have a function return multiple values is a poor programming practice. Also, functions should be free from side effects, which change the values of variables not local to the subprogram.
An IN parameter lets you pass values to the subprogram being called. Inside the subprogram, an IN parameter acts like a constant. Therefore, it cannot be assigned a value. For example, the following assignment statement causes a compilation error:
PROCEDURE debit_account (acct_id IN INTEGER, amount IN REAL) IS minimum_purchase CONSTANT REAL DEFAULT 10.0; service_charge CONSTANT REAL DEFAULT 0.50; BEGIN IF amount < minimum_purchase THEN amount := amount + service_charge; -- causes compilation error END IF; ... END debit_account;
The actual parameter that corresponds to an IN formal parameter can be a constant, literal, initialized variable, or expression. Unlike OUT and IN OUT parameters, IN parameters can be initialized to default values. For more information, see "Using Default Values for Subprogram Parameters".
An OUT parameter lets you return values to the caller of a subprogram. Inside the subprogram, an OUT parameter acts like a variable. That means you can use an OUT formal parameter as if it were a local variable. You can change its value or reference the value in any way, as the following example shows:
PROCEDURE calc_bonus (emp_id IN INTEGER, bonus OUT REAL) IS hire_date DATE; bonus_missing EXCEPTION; BEGIN SELECT sal * 0.10, hiredate INTO bonus, hire_date FROM emp WHERE empno = emp_id; IF bonus IS NULL THEN RAISE bonus_missing; END IF; IF MONTHS_BETWEEN(SYSDATE, hire_date) > 60 THEN bonus := bonus + 500; END IF; ... EXCEPTION WHEN bonus_missing THEN ... END calc_bonus;
The actual parameter that corresponds to an OUT formal parameter must be a variable; it cannot be a constant or an expression. For example, the following procedure call is illegal:
calc_bonus(7499, salary + commission); -- causes compilation error
An OUT actual parameter can have a value before the subprogram is called. However, when you call the subprogram, the value is lost unless you specify the compiler hint NOCOPY (see "Passing Large Data Structures with the NOCOPY Compiler Hint") or the subprogram exits with an unhandled exception.
Like variables, OUT formal parameters are initialized to NULL. So, the datatype of an OUT formal parameter cannot be a subtype defined as NOT NULL (that includes the built-in subtypes NATURALN and POSITIVEN). Otherwise, when you call the subprogram, PL/SQL raises VALUE_ERROR. An example follows:
DECLARE SUBTYPE Counter IS INTEGER NOT NULL; rows Counter := 0; PROCEDURE count_emps (n OUT Counter) IS BEGIN SELECT COUNT(*) INTO n FROM emp; END; BEGIN count_emps(rows); -- raises VALUE_ERROR
Before exiting a subprogram, explicitly assign values to all OUT formal parameters. Otherwise, the corresponding actual parameters will be null. If you exit successfully, PL/SQL assigns values to the actual parameters. However, if you exit with an unhandled exception, PL/SQL does not assign values to the actual parameters.
An IN OUT parameter lets you pass initial values to the subprogram being called and return updated values to the caller. Inside the subprogram, an IN OUT parameter acts like an initialized variable. Therefore, it can be assigned a value and its value can be assigned to another variable.
The actual parameter that corresponds to an IN OUT formal parameter must be a variable; it cannot be a constant or an expression.
If you exit a subprogram successfully, PL/SQL assigns values to the actual parameters. However, if you exit with an unhandled exception, PL/SQL does not assign values to the actual parameters.
Table 8-1 summarizes all you need to know about the parameter modes.
Suppose a subprogram declares an IN parameter, an OUT parameter, and an IN OUT parameter. When you call the subprogram, the IN parameter is passed by reference. That is, a pointer to the IN actual parameter is passed to the corresponding formal parameter. So, both parameters reference the same memory location, which holds the value of the actual parameter.
By default, the OUT and IN OUT parameters are passed by value. That is, the value of the IN OUT actual parameter is copied into the corresponding formal parameter. Then, if the subprogram exits normally, the values assigned to the OUT and IN OUT formal parameters are copied into the corresponding actual parameters.
When the parameters hold large data structures such as collections, records, and instances of object types, all this copying slows down execution and uses up memory. To prevent that, you can specify the NOCOPY hint, which allows the PL/SQL compiler to pass OUT and IN OUT parameters by reference.
In the following example, you ask the compiler to pass IN OUT parameter my_staff by reference instead of by value:
DECLARE TYPE Staff IS VARRAY(200) OF Employee; PROCEDURE reorganize (my_staff IN OUT NOCOPY Staff) IS ...
Remember, NOCOPY is a hint, not a directive. So, the compiler might pass my_staff by value despite your request. Usually, however, NOCOPY succeeds. So, it can benefit any PL/SQL application that passes around large data structures.
In the example below, 25000 records are loaded into a local nested table, which is passed to two local procedures that do nothing but execute NULL statements. However, a call to one procedure takes 21 seconds because of all the copying. With NOCOPY, a call to the other procedure takes much less than 1 second.
SQL> SET SERVEROUTPUT ON SQL> GET test.sql 1 DECLARE 2 TYPE EmpTabTyp IS TABLE OF emp%ROWTYPE; 3 emp_tab EmpTabTyp := EmpTabTyp(NULL); -- initialize 4 t1 NUMBER(5); 5 t2 NUMBER(5); 6 t3 NUMBER(5); 7 PROCEDURE get_time (t OUT NUMBER) IS 8 BEGIN SELECT TO_CHAR(SYSDATE,'SSSSS') INTO t FROM dual; END; 9 PROCEDURE do_nothing1 (tab IN OUT EmpTabTyp) IS 10 BEGIN NULL; END; 11 PROCEDURE do_nothing2 (tab IN OUT NOCOPY EmpTabTyp) IS 12 BEGIN NULL; END; 13 BEGIN 14 SELECT * INTO emp_tab(1) FROM emp WHERE empno = 7788; 15 emp_tab.EXTEND(24999, 1); -- copy element 1 into 2..25000 16 get_time(t1); 17 do_nothing1(emp_tab); -- pass IN OUT parameter 18 get_time(t2); 19 do_nothing2(emp_tab); -- pass IN OUT NOCOPY parameter 20 get_time(t3); 21 dbms_output.put_line('Call Duration (secs)'); 22 dbms_output.put_line('--------------------'); 23 dbms_output.put_line('Just IN OUT: ' || TO_CHAR(t2 - t1)); 24 dbms_output.put_line('With NOCOPY: ' || TO_CHAR(t3 - t2)); 25* END; SQL> / Call Duration (secs) -------------------- Just IN OUT: 21 With NOCOPY: 0
NOCOPY lets you trade well-defined exception semantics for better performance. Its use affects exception handling in the following ways:
NOCOPY is a hint, not a directive, the compiler can pass NOCOPY parameters to a subprogram by value or by reference. So, if the subprogram exits with an unhandled exception, you cannot rely on the values of the NOCOPY actual parameters.OUT and IN OUT formal parameters are not copied into the corresponding actual parameters, and changes appear to roll back. However, when you specify NOCOPY, assignments to the formal parameters immediately affect the actual parameters as well. So, if the subprogram exits with an unhandled exception, the (possibly unfinished) changes are not "rolled back."NOCOPY parameters to a remote site, those parameters will no longer be passed by reference.Also, the use of NOCOPY increases the likelihood of parameter aliasing. For more information, see "Understanding Subprogram Parameter Aliasing".
In the following cases, the PL/SQL compiler ignores the NOCOPY hint and uses the by-value parameter-passing method (no error is generated):
NOT NULL for example). This restriction does not extend to constrained elements or attributes. Also, it does not apply to size-constrained character strings.%ROWTYPE or %TYPE, and constraints on corresponding fields in the records differ.FOR loop, and constraints on corresponding fields in the records differ.As the example below shows, you can initialize IN parameters to default values. That way, you can pass different numbers of actual parameters to a subprogram, accepting or overriding the default values as you please. Moreover, you can add new formal parameters without having to change every call to the subprogram.
PROCEDURE create_dept ( new_dname VARCHAR2 DEFAULT 'TEMP', new_loc VARCHAR2 DEFAULT 'TEMP') IS BEGIN INSERT INTO dept VALUES (deptno_seq.NEXTVAL, new_dname, new_loc); ... END;
If an actual parameter is not passed, the default value of its corresponding formal parameter is used. Consider the following calls to create_dept:
create_dept; create_dept('MARKETING'); create_dept('MARKETING', 'NEW YORK');
The first call passes no actual parameters, so both default values are used. The second call passes one actual parameter, so the default value for new_loc is used. The third call passes two actual parameters, so neither default value is used.
Usually, you can use positional notation to override the default values of formal parameters. However, you cannot skip a formal parameter by leaving out its actual parameter. For example, the following call incorrectly associates the actual parameter 'NEW YORK' with the formal parameter new_dname:
create_dept('NEW YORK'); -- incorrect
You cannot solve the problem by leaving a placeholder for the actual parameter. For example, the following call is not allowed:
create_dept(, 'NEW YORK'); -- not allowed
In such cases, you must use named notation, as follows:
create_dept(new_loc => 'NEW YORK');
Also, you cannot assign a null to an uninitialized formal parameter by leaving out its actual parameter. For example, given the declaration
DECLARE FUNCTION gross_pay ( emp_id IN NUMBER, st_hours IN NUMBER DEFAULT 40, ot_hours IN NUMBER) RETURN REAL IS BEGIN ... END;
the following function call does not assign a null to ot_hours:
IF gross_pay(emp_num) > max_pay THEN ... -- not allowed
Instead, you must pass the null explicitly, as in
IF gross_pay(emp_num, ot_hour => NULL) > max_pay THEN ...
or you can initialize ot_hours to NULL, as follows:
ot_hours IN NUMBER DEFAULT NULL;
Finally, when creating a stored subprogram, you cannot use host variables (bind variables) in the DEFAULT clause. The following SQL*Plus example causes a bad bind variable error because at the time of creation, num is just a placeholder whose value might change:
SQL> VARIABLE num NUMBER SQL> CREATE FUNCTION gross_pay (emp_id IN NUMBER DEFAULT :num, ...
To optimize a subprogram call, the PL/SQL compiler can choose between two methods of parameter passing. With the by-value method, the value of an actual parameter is passed to the subprogram. With the by-reference method, only a pointer to the value is passed, in which case the actual and formal parameters reference the same item.
The NOCOPY compiler hint increases the possibility of aliasing (that is, having two different names refer to the same memory location). This can occur when a global variable appears as an actual parameter in a subprogram call and then is referenced within the subprogram. The result is indeterminate because it depends on the method of parameter passing chosen by the compiler.
In the example below, procedure add_entry refers to varray lexicon in two different ways: as a parameter and as a global variable. So, when add_entry is called, the identifiers word_list and lexicon name the same varray.
DECLARE TYPE Definition IS RECORD ( word VARCHAR2(20), meaning VARCHAR2(200)); TYPE Dictionary IS VARRAY(2000) OF Definition; lexicon Dictionary := Dictionary(); PROCEDURE add_entry (word_list IN OUT NOCOPY Dictionary) IS BEGIN word_list(1).word := 'aardvark'; lexicon(1).word := 'aardwolf'; END; BEGIN lexicon.EXTEND; add_entry(lexicon); dbms_output.put_line(lexicon(1).word); -- prints 'aardvark' if parameter was passed by value -- prints 'aardwolf' if parameter was passed by reference END;
The result depends on the method of parameter passing chosen by the compiler. If the compiler chooses the by-value method, word_list and lexicon are separate copies of the same varray. So, changing one does not affect the other. But, if the compiler chooses the by-reference method, word_list and lexicon are just different names for the same varray. (Hence, the term "aliasing.") So, changing the value of lexicon(1) also changes the value of word_list(1).
Aliasing can also occur when the same actual parameter appears more than once in a subprogram call. In the example below, n2 is an IN OUT parameter, so the value of the actual parameter is not updated until the procedure exits. That is why the first put_line prints 10 (the initial value of n) and the third put_line prints 20. However, n3 is a NOCOPY parameter, so the value of the actual parameter is updated immediately. That is why the second put_line prints 30.
DECLARE n NUMBER := 10; PROCEDURE do_something ( n1 IN NUMBER, n2 IN OUT NUMBER, n3 IN OUT NOCOPY NUMBER) IS BEGIN n2 := 20; dbms_output.put_line(n1); -- prints 10 n3 := 30; dbms_output.put_line(n1); -- prints 30 END; BEGIN do_something(n, n, n); dbms_output.put_line(n); -- prints 20 END;
Because they are pointers, cursor variables also increase the possibility of aliasing. Consider the example below. After the assignment, emp_cv2 is an alias of emp_cv1 because both point to the same query work area. So, both can alter its state. That is why the first fetch from emp_cv2 fetches the third row (not the first) and why the second fetch from emp_cv2 fails after you close emp_cv1.
PROCEDURE get_emp_data ( emp_cv1 IN OUT EmpCurTyp, emp_cv2 IN OUT EmpCurTyp) IS emp_rec emp%ROWTYPE; BEGIN OPEN emp_cv1 FOR SELECT * FROM emp; emp_cv2 := emp_cv1; FETCH emp_cv1 INTO emp_rec; -- fetches first row FETCH emp_cv1 INTO emp_rec; -- fetches second row FETCH emp_cv2 INTO emp_rec; -- fetches third row CLOSE emp_cv1; FETCH emp_cv2 INTO emp_rec; -- raises INVALID_CURSOR ... END;
PL/SQL lets you overload subprogram names and type methods. That is, you can use the same name for several different subprograms as long as their formal parameters differ in number, order, or datatype family.
Suppose you want to initialize the first n rows in two index-by tables that were declared as follows:
DECLARE TYPE DateTabTyp IS TABLE OF DATE INDEX BY BINARY_INTEGER; TYPE RealTabTyp IS TABLE OF REAL INDEX BY BINARY_INTEGER; hiredate_tab DateTabTyp; sal_tab RealTabTyp; BEGIN ... END;
You might write the following procedure to initialize the index-by table named hiredate_tab:
PROCEDURE initialize (tab OUT DateTabTyp, n INTEGER) IS BEGIN FOR i IN 1..n LOOP tab(i) := SYSDATE; END LOOP; END initialize;
And, you might write the next procedure to initialize the index-by table named sal_tab:
PROCEDURE initialize (tab OUT RealTabTyp, n INTEGER) IS BEGIN FOR i IN 1..n LOOP tab(i) := 0.0; END LOOP; END initialize;
Because the processing in these two procedures is the same, it is logical to give them the same name.
You can place the two overloaded initialize procedures in the same block, subprogram, or package. PL/SQL determines which of the two procedures is being called by checking their formal parameters. In the following example, the version of initialize that PL/SQL uses depends on whether you call the procedure with a DateTabTyp or RealTabTyp parameter:
DECLARE TYPE DateTabTyp IS TABLE OF DATE INDEX BY BINARY_INTEGER; TYPE RealTabTyp IS TABLE OF REAL INDEX BY BINARY_INTEGER; hiredate_tab DateTabTyp; comm_tab RealTabTyp; indx BINARY_INTEGER; PROCEDURE initialize (tab OUT DateTabTyp, n INTEGER) IS BEGIN ... END; PROCEDURE initialize (tab OUT RealTabTyp, n INTEGER) IS BEGIN ... END; BEGIN indx := 50; initialize(hiredate_tab, indx); -- calls first version initialize(comm_tab, indx); -- calls second version ... END;
Only local or packaged subprograms, or type methods, can be overloaded. Therefore, you cannot overload standalone subprograms. Also, you cannot overload two subprograms if their formal parameters differ only in name or parameter mode. For example, you cannot overload the following two procedures:
DECLARE ... PROCEDURE reconcile (acct_no IN INTEGER) IS BEGIN ... END; PROCEDURE reconcile (acct_no OUT INTEGER) IS BEGIN ... END;
You cannot overload two subprograms if their formal parameters differ only in datatype and the different datatypes are in the same family. For instance, you cannot overload the following procedures because the datatypes INTEGER and REAL are in the same family:
DECLARE ... PROCEDURE charge_back (amount INTEGER) IS BEGIN ... END; PROCEDURE charge_back (amount REAL) IS BEGIN ... END;
Likewise, you cannot overload two subprograms if their formal parameters differ only in subtype and the different subtypes are based on types in the same family. For example, you cannot overload the following procedures because the base types CHAR and LONG are in the same family:
DECLARE SUBTYPE Delimiter IS CHAR; SUBTYPE Text IS LONG; ... PROCEDURE scan (x Delimiter) IS BEGIN ... END; PROCEDURE scan (x Text) IS BEGIN ... END;
Finally, you cannot overload two functions that differ only in return type (the datatype of the return value) even if the types are in different families. For example, you cannot overload the following functions:
DECLARE ... FUNCTION acct_ok (acct_id INTEGER) RETURN BOOLEAN IS BEGIN ... END; FUNCTION acct_ok (acct_id INTEGER) RETURN INTEGER IS BEGIN ... END;
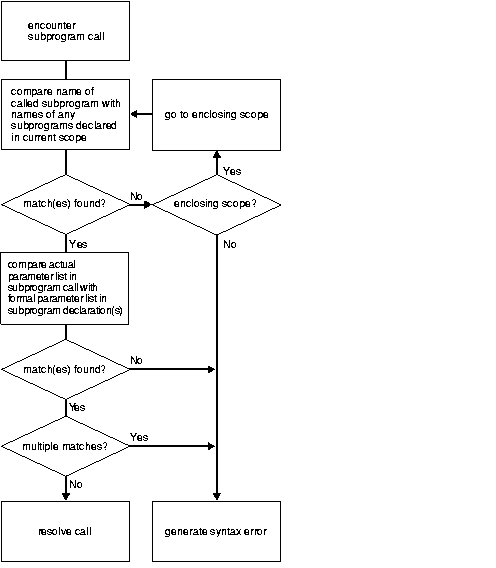
Figure 8-1 shows how the PL/SQL compiler resolves subprogram calls. When the compiler encounters a procedure or function call, it tries to find a declaration that matches the call. The compiler searches first in the current scope and then, if necessary, in successive enclosing scopes. The compiler stops searching if it finds one or more subprogram declarations in which the subprogram name matches the name of the called subprogram.
To resolve a call among possibly like-named subprograms at the same level of scope, the compiler must find an exact match between the actual and formal parameters. That is, they must match in number, order, and datatype (unless some formal parameters were assigned default values). If no match is found or if multiple matches are found, the compiler generates a semantic error.
In the following example, you call the enclosing procedure swap from within the function reconcile. However, the compiler generates an error because neither declaration of swap within the current scope matches the procedure call:
PROCEDURE swap (n1 NUMBER, n2 NUMBER) IS num1 NUMBER; num2 NUMBER; FUNCTION balance (...) RETURN REAL IS PROCEDURE swap (d1 DATE, d2 DATE) IS BEGIN ... END; PROCEDURE swap (b1 BOOLEAN, b2 BOOLEAN) IS BEGIN ... END; BEGIN ... swap(num1, num2); RETURN ... END balance; BEGIN ... END;
The overloading algorithm allows substituting a subtype value for a formal parameter that is a supertype. This capability is known as substitutability. If more than one instance of an overloaded procedure matches the procedure call, the following rules apply to determine which procedure is called:
If the only difference in the signatures of the overloaded procedures is that some parameters are object types from the same supertype-subtype hierarchy, the closest match is used. The closest match is one where all the parameters are at least as close as any other overloaded instance, as determined by the depth of inheritance between the subtype and supertype, and at least one parameter is closer.
A semantic error occurs when two overloaded instances match, and some argument types are closer in one overloaded procedure to the actual arguments than in any other instance.
A semantic error also occurs if some parameters are different in their position within the object type hierarchy, and other parameters are of different datatypes so that an implicit conversion would be necessary.
For example, here we create a type hierarchy with 3 levels:
CREATE TYPE super_t AS object (n NUMBER) NOT final; CREATE OR replace TYPE sub_t under super_t (n2 NUMBER) NOT final; CREATE OR replace TYPE final_t under sub_t (n3 NUMBER);
We declare two overloaded instances of a function, where the only difference in argument types is their position in this type hierarchy:
CREATE PACKAGE p IS FUNCTION foo (arg super_t) RETURN NUMBER; FUNCTION foo (arg sub_t) RETURN NUMBER; END; / CREATE PACKAGE BODY p IS FUNCTION foo (arg super_t) RETURN NUMBER IS BEGIN RETURN 1; END; FUNCTION foo (arg sub_t) RETURN NUMBER IS BEGIN RETURN 2; END; END; /
We declare a variable of type final_t, then call the overloaded function. The instance of the function that is executed is the one that accepts a sub_t parameter, because that type is closer to final_t in the hierarchy than super_t is.
SQL> set serveroutput on SQL> declare v final_t := final_t(1,2,3); begin dbms_output.put_line(p.foo(v)); end; / 2
In the previous example, the choice of which instance to call is made at compile time. In the following example, this choice is made dynamically.
CREATE TYPE super_t2 AS object (n NUMBER, MEMBER FUNCTION foo RETURN NUMBER) NOT final; / CREATE TYPE BODY super_t2 AS MEMBER FUNCTION foo RETURN NUMBER IS BEGIN RETURN 1; END; END; / CREATE OR replace TYPE sub_t2 under super_t2 (n2 NUMBER, OVERRIDING MEMBER FUNCTION foo RETURN NUMBER) NOT final; / CREATE TYPE BODY sub_t2 AS OVERRIDING MEMBER FUNCTION foo RETURN NUMBER IS BEGIN RETURN 2; END; END; / CREATE OR replace TYPE final_t2 under sub_t2 (n3 NUMBER); /
We declare v as an instance of super_t2, but because we assign a value of sub_t2 to it, the appropriate instance of the function is called. This feature is known as dynamic dispatch.
SQL> set serveroutput on declare v super_t2 := final_t2(1,2,3); begin dbms_output.put_line(v.foo); end; / 2
This section describes table functions. It also explains the generic datatypes ANYTYPE, ANYDATA, and ANYDATASET, which are likely to be used with table functions.
Major topics covered are:
Table functions are functions that produce a collection of rows (either a nested table or a varray) that can be queried like a physical database table or assigned to a PL/SQL collection variable. You can use a table function like the name of a database table, in the FROM clause of a query, or like a column name in the SELECT list of a query.
A table function can take a collection of rows as input. An input collection parameter can be either a collection type (such as a VARRAY or a PL/SQL table) or a REF CURSOR.
Execution of a table function can be parallelized, and returned rows can be streamed directly to the next process without intermediate staging. Rows from a collection returned by a table function can also be pipelined--that is, iteratively returned as they are produced instead of in a batch after all processing of the table function's input is completed.
Streaming, pipelining, and parallel execution of table functions can improve performance:
Figure 8-2 shows a typical data-processing scenario in which data goes through several (in this case, three) transformations, implemented by table functions, before finally being loaded into a database. In this scenario, the table functions are not parallelized, and the entire result collection must be staged using a temporary table after each transformation.

By contrast, Figure 8-3, below, shows how streaming and parallel execution can streamline the same scenario.
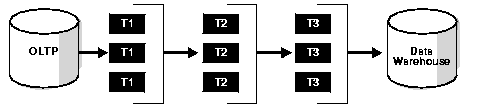
Table functions return a collection type instance representing rows in a table. They can be queried like a table by calling the function in the FROM clause of a query, enclosed by the TABLE keyword. They can be assigned to a PL/SQL collection variable by calling the function in the SELECT list of a query.
The following example shows a table function GetBooks that takes a CLOB as input and returns an instance of the collection type BookSet_t. The CLOB column stores a catalog listing of books in some format (either proprietary or following a standard such as XML). The table function returns all the catalogs and their corresponding book listings.
The collection type BookSet_t is defined as:
CREATE TYPE Book_t AS OBJECT ( name VARCHAR2(100), author VARCHAR2(30), abstract VARCHAR2(1000)); CREATE TYPE BookSet_t AS TABLE OF Book_t;
The CLOBs are stored in a table Catalogs:
CREATE TABLE Catalogs ( name VARCHAR2(30), cat CLOB);
Function GetBooks is defined as follows:
CREATE FUNCTION GetBooks(a CLOB) RETURN BookSet_t;
The query below returns all the catalogs and their corresponding book listings.
SELECT c.name, Book.name, Book.author, Book.abstract FROM Catalogs c, TABLE(GetBooks(c.cat)) Book;
The following example shows how you can assign the result of a table function to a PL/SQL collection variable. Because the table function is called from the SELECT list of the query, you do not need the TABLE keyword.
create type numset_t as table of number; / create function f1(x number) return numset_t pipelined is begin for i in 1..x loop pipe row(i); end loop; return; end; / -- pipelined function in from clause select * from table(f1(3)); COLUMN_VALUE ------------ 1 2 3 3 rows selected. -- pipelined function in select list select f1(3) from dual; F1(3) --------------------------------- NUMSET_T(1, 2, 3) -- Since the function returns a collection, we can assign -- the result to a PL/SQL variable. declare func_result numset_t; begin select f1(3) into func_result from dual; end; /
Data is said to be pipelined if it is consumed by a consumer (transformation) as soon as the producer (transformation) produces it, without being staged in tables or a cache before being input to the next transformation.
Pipelining enables a table function to return rows faster and can reduce the memory required to cache a table function's results.
A pipelined table function can return the table function's result collection in subsets. The returned collection behaves like a stream that can be fetched from on demand. This makes it possible to use a table function like a virtual table.
Pipelined table functions can be implemented in two ways:
In the rest of this chapter, the term table function is used to refer to a pipelined table function--that is, a table function that returns a collection in an iterative, pipelined way.
A pipelined table function can accept any argument that regular functions accept. A table function that accepts a REF CURSOR as an argument can serve as a transformation function. That is, it can use the REF CURSOR to fetch the input rows, perform some transformation on them, and then pipeline the results out (using either the interface approach or the native PL/SQL approach).
For example, the following code sketches the declarations that define a StockPivot function. This function converts a row of the type (Ticker, OpenPrice, ClosePrice) into two rows of the form (Ticker, PriceType, Price). Calling StockPivot for the row ("ORCL", 41, 42) generates two rows: ("ORCL", "O", 41) and ("ORCL", "C", 42).
Input data for the table function might come from a source such as table StockTable:
CREATE TABLE StockTable ( ticker VARCHAR(4), open_price NUMBER, close_price NUMBER );
Here are the declarations. See "Returning Results from Table Functions" for the function bodies.
-- Create the types for the table function's output collection -- and collection elements CREATE TYPE TickerType AS OBJECT ( ticker VARCHAR2(4), PriceType VARCHAR2(1), price NUMBER ); CREATE TYPE TickerTypeSet AS TABLE OF TickerType; -- Define the ref cursor type CREATE PACKAGE refcur_pkg IS TYPE refcur_t IS REF CURSOR RETURN StockTable%ROWTYPE; END refcur_pkg; / -- Create the table function CREATE FUNCTION StockPivot(p refcur_pkg.refcur_t) RETURN TickerTypeSet PIPELINED ... ; /
Here is an example of a query that uses the StockPivot table function:
SELECT * FROM TABLE(StockPivot(CURSOR(SELECT * FROM StockTable)));
In the query above, the pipelined table function StockPivot fetches rows from the CURSOR subquery SELECT * FROM StockTable, performs the transformation, and pipelines the results back to the user as a table. The function produces two output rows (collection elements) for each input row.
Note that when a CURSOR subquery is passed from SQL to a REF CURSOR function argument as in the example above, the referenced cursor is already open when the function begins executing.
You declare a pipelined table function by specifying the PIPELINED keyword. This keyword indicates that the function will return rows iteratively. The return type of the pipelined table function must be a collection type, such as a nested table or a varray. You can declare this collection at the schema level, or inside a package. Inside the function, you return individual elements of the collection type.
For example, here are declarations for two pipelined table functions. (The function bodies are shown in later examples.)
CREATE FUNCTION GetBooks(cat CLOB) RETURN BookSet_t PIPELINED IS ...; CREATE FUNCTION StockPivot(p refcur_pkg.refcur_t) RETURN TickerTypeSet PIPELINED IS...;
In PL/SQL, the PIPE ROW statement causes a table function to pipe a row and continue processing. The statement enables a PL/SQL table function to return rows as soon as they are produced. (For performance, the PL/SQL runtime system provides the rows to the consumer in batches.) For example:
CREATE FUNCTION StockPivot(p refcur_pkg.refcur_t) RETURN TickerTypeSet PIPELINED IS out_rec TickerType := TickerType(NULL,NULL,NULL); in_rec p%ROWTYPE; BEGIN LOOP FETCH p INTO in_rec; EXIT WHEN p%NOTFOUND; -- first row out_rec.ticker := in_rec.Ticker; out_rec.PriceType := 'O'; out_rec.price := in_rec.OpenPrice; PIPE ROW(out_rec); -- second row out_rec.PriceType := 'C'; out_rec.Price := in_rec.ClosePrice; PIPE ROW(out_rec); END LOOP; CLOSE p; RETURN; END; /
In the example, the PIPE ROW(out_rec) statement pipelines data out of the PL/SQL table function. out_rec is a record, and its type matches the type of an element of the output collection.
The PIPE ROW statement may be used only in the body of pipelined table functions; an error is raised if it is used anywhere else. The PIPE ROW statement can be omitted for a pipelined table function that returns no rows.
A pipelined table function must have a RETURN statement that does not return a value. The RETURN statement transfers the control back to the consumer and ensures that the next fetch gets a NO_DATA_FOUND exception.
Oracle has three special SQL datatypes that enable you to dynamically encapsulate and access type descriptions, data instances, and sets of data instances of any other SQL type, including object and collection types. You can also use these three special types to create anonymous (that is, unnamed) types, including anonymous collection types. The types are SYS.ANYTYPE, SYS.ANYDATA, and SYS.ANYDATASET. The SYS.ANYDATA type can be useful in some situations as a return value from table functions.
| See Also:
Oracle9i Supplied PL/SQL Packages and Types Reference for information about the interfaces to the |
With serial execution, results are pipelined from one PL/SQL table function to another using an approach similar to co-routine execution. For example, the following statement pipelines results from function g to function f:
SELECT * FROM TABLE(f(CURSOR(SELECT * FROM TABLE(g()))));
Parallel execution works similarly except that each function executes in a different process (or set of processes).
Pipelined table functions are used in the FROM clause of SELECT statements. The result rows are retrieved by Oracle iteratively from the table function implementation. For example:
SELECT x.Ticker, x.Price FROM TABLE(StockPivot( CURSOR(SELECT * FROM StockTable))) x WHERE x.PriceType='C';
Multiple invocations of a table function, either within the same query or in separate queries result in multiple executions of the underlying implementation. By default, there is no buffering or reuse of rows.
For example,
SELECT * FROM TABLE(f(...)) t1, TABLE(f(...)) t2 WHERE t1.id = t2.id; SELECT * FROM TABLE(f()); SELECT * FROM TABLE(f());
However, if the output of a table function is determined solely by the values passed into it as arguments, such that the function always produces exactly the same result value for each respective combination of values passed in, you can declare the function DETERMINISTIC, and Oracle will automatically buffer rows for it. Note, though, that the database has no way of knowing whether a function marked DETERMINISTIC really is DETERMINISTIC, and if one is not, results will be unpredictable.
PL/SQL cursors and ref cursors can be defined for queries over table functions. For example:
OPEN c FOR SELECT * FROM TABLE(f(...));
Cursors over table functions have the same fetch semantics as ordinary cursors. REF CURSOR assignments based on table functions do not have any special semantics.
However, the SQL optimizer will not optimize across PL/SQL statements. For example:
BEGIN OPEN r FOR SELECT * FROM TABLE(f(CURSOR(SELECT * FROM tab))); SELECT * BULK COLLECT INTO rec_tab FROM TABLE(g(r)); END;
does not execute as well as:
SELECT * FROM TABLE(g(CURSOR(SELECT * FROM TABLE(f(CURSOR(SELECT * FROM tab))))));
This is so even ignoring the overhead associated with executing two SQL statements and assuming that the results can be pipelined between the two statements.
You can pass a set of rows to a PL/SQL function in a REF CURSOR parameter. For example, this function is declared to accept an argument of the predefined weakly typed REF CURSOR type SYS_REFCURSOR:
FUNCTION f(p1 IN SYS_REFCURSOR) RETURN ... ;
Results of a subquery can be passed to a function directly:
SELECT * FROM TABLE(f(CURSOR(SELECT empno FROM tab)));
In the example above, the CURSOR keyword is required to indicate that the results of a subquery should be passed as a REF CURSOR parameter.
A predefined weak REF CURSOR type SYS_REFCURSOR is also supported. With SYS_REFCURSOR, you do not need to first create a REF CURSOR type in a package before you can use it.
To use a strong REF CURSOR type, you still must create a PL/SQL package and declare a strong REF CURSOR type in it. Also, if you are using a strong REF CURSOR type as an argument to a table function, then the actual type of the REF CURSOR argument must match the column type, or an error is generated. Weak REF CURSOR arguments to table functions can only be partitioned using the PARTITION BY ANY clause. You cannot use range or hash partitioning for weak REF CURSOR arguments.
PL/SQL functions can accept multiple REF CURSOR input variables:
CREATE FUNCTION g(p1 pkg.refcur_t1, p2 pkg.refcur_t2) RETURN... PIPELINED ... ;
Function g can be invoked as follows:
SELECT * FROM TABLE(g(CURSOR(SELECT empno FROM tab), CURSOR(SELECT * FROM emp));
You can pass table function return values to other table functions by creating a REF CURSOR that iterates over the returned data:
SELECT * FROM TABLE(f(CURSOR(SELECT * FROM TABLE(g(...)))));
You can explicitly open a REF CURSOR for a query and pass it as a parameter to a table function:
BEGIN OPEN r FOR SELECT * FROM TABLE(f(...)); -- Must return a single row result set. SELECT * INTO rec FROM TABLE(g(r)); END;
In this case, the table function closes the cursor when it completes, so your program should not explicitly try to close the cursor.
A table function can compute aggregate results using the input ref cursor. The following example computes a weighted average by iterating over a set of input rows.
DROP TABLE gradereport; CREATE TABLE gradereport (student VARCHAR2(30), subject VARCHAR2(30), weight NUMBER, grade NUMBER); INSERT INTO gradereport VALUES('Mark', 'Physics', 4, 4); INSERT INTO gradereport VALUES('Mark','Chemistry', 4,3); INSERT INTO gradereport VALUES('Mark','Maths', 3,3); INSERT INTO gradereport VALUES('Mark','Economics', 3,4); CREATE OR replace TYPE gpa AS TABLE OF NUMBER; / CREATE OR replace FUNCTION weighted_average(input_values sys_refcursor) RETURN gpa PIPELINED IS grade NUMBER; total NUMBER := 0; total_weight NUMBER := 0; weight NUMBER := 0; BEGIN -- The function accepts a ref cursor and loops through all the input rows. LOOP FETCH input_values INTO weight, grade; EXIT WHEN input_values%NOTFOUND; -- Accumulate the weighted average. total_weight := total_weight + weight; total := total + grade*weight; END LOOP; PIPE ROW (total / total_weight); -- The function returns a single result. RETURN; END; / show errors; -- The result comes back as a nested table with a single row. -- COLUMN_VALUE is a keyword that returns the contents of a nested table. select weighted_result.column_value from table(weighted_average(cursor(select weight,grade from gradereport))) weighted_result; COLUMN_VALUE ------------ 3.5
To execute DML statements, a table function must be declared with the autonomous transaction pragma . This pragma causes the function to execute in an autonomous transaction not shared by other processes.
Use the following syntax to declare a table function with the autonomous transaction pragma:
CREATE FUNCTION f(p SYS_REFCURSOR) return CollType PIPELINED IS PRAGMA AUTONOMOUS_TRANSACTION; BEGIN ... END;
During parallel execution, each instance of the table function creates an independent transaction.
Table functions cannot be the target table in UPDATE, INSERT, or DELETE statements. For example, the following statements will raise an error:
UPDATE F(CURSOR(SELECT * FROM tab)) SET col = value; INSERT INTO f(...) VALUES ('any', 'thing');
However, you can create a view over a table function and use INSTEAD OF triggers to update it. For example:
CREATE VIEW BookTable AS SELECT x.Name, x.Author FROM TABLE(GetBooks('data.txt')) x;
The following INSTEAD OF trigger is fired when the user inserts a row into the BookTable view:
CREATE TRIGGER BookTable_insert INSTEAD OF INSERT ON BookTable REFERENCING NEW AS n FOR EACH ROW BEGIN ... END; INSERT INTO BookTable VALUES (...);
INSTEAD OF triggers can be defined for all DML operations on a view built on a table function.
Exception handling in table functions works just as it does with ordinary user-defined functions.
Some languages, such as C and Java, provide a mechanism for user-supplied exception handling. If an exception raised within a table function is handled, the table function executes the exception handler and continues processing. Exiting the exception handler takes control to the enclosing scope. If the exception is cleared, execution proceeds normally.
An unhandled exception in a table function causes the parent transaction to roll back.
For a table function to be executed in parallel, it must have a partitioned input parameter. Parallelism is turned on for a table function if, and only if, both the following conditions are met:
PARALLEL_ENABLE clause in its declarationREF CURSOR argument is specified with a PARTITION BY clause
If the PARTITION BY clause is not specified for any input REF CURSOR as part of the PARALLEL_ENABLE clause, the SQL compiler cannot determine how to partition the data correctly. Note that only strongly typed REF CURSOR arguments can be specified in the PARTITION BY clause, unless you use PARTITION BY ANY.
With parallel execution of a function that appears in the SELECT list, execution of the function is pushed down to and conducted by multiple slave scan processes. These each execute the function on a segment of the function's input data.
For example, the query
SELECT f(col1) FROM tab;
is parallelized if f is a pure function. The SQL executed by a slave scan process is similar to:
SELECT f(col1) FROM tab WHERE ROWID BETWEEN :b1 AND :b2;
Each slave scan operates on a range of rowids and applies function f to each contained row. Function f is then executed by the scan processes; it does not run independently of them.
Unlike a function that appears in the SELECT list, a table function is called in the FROM clause and returns a collection. This affects the way that table function input data is partitioned among slave scans because the partitioning approach must be appropriate for the operation that the table function performs. (For example, an ORDER BY operation requires input to be range-partitioned, whereas a GROUP BY operation requires input to be hash partitioned.)
A table function itself specifies in its declaration the partitioning approach that is appropriate for it. (See "Input Data Partitioning".) The function is then executed in a two-stage operation. First, one set of slave processes partitions the data as directed in the function's declaration; then a second set of slave processes executes the table function in parallel on the partitioned data.
For example, the table function in the following query has a REF CURSOR parameter:
SELECT * FROM TABLE(f(CURSOR(SELECT * FROM tab)));
The scan is performed by one set of slave processes, which redistributes the rows (based on the partitioning method specified in the function declaration) to a second set of slave processes that actually executes function f in parallel.
The table function declaration can specify data partitioning for exactly one REF CURSOR parameter. The syntax to do this is as follows:
CREATE FUNCTION f(pref cursor type) RETURNrec_tab_typePIPELINED PARALLEL_ENABLE(PARTITION p BY [{HASH | RANGE} (column list) | ANY ]) IS BEGIN ... END;
The PARTITION...BY phrase in the PARALLEL_ENABLE clause specifies which one of the input cursors to partition and what columns to use for partitioning.
When explicit column names are specified in the column list, the partitioning method can be RANGE or HASH. The input rows will be hash- or range-partitioned on the columns specified.
The ANY keyword indicates that the function behavior is independent of the partitioning of the input data. When this keyword is used, the runtime system randomly partitions the data among the slaves. This keyword is appropriate for use with functions that take in one row, manipulate its columns, and generate output row(s) based on the columns of this row only.
For example, the pivot-like function StockPivot shown below takes as input a row of the type:
(Ticker varchar(4), OpenPrice number, ClosePrice number)
and generates rows of the type:
(Ticker varchar(4), PriceType varchar(1), Price number).
So the row ("ORCL", 41, 42) generates two rows ("ORCL", "O", 41) and ("ORCL", "C", 42).
CREATE FUNCTION StockPivot(p refcur_pkg.refcur_t) RETURN rec_tab_type PIPELINED PARALLEL_ENABLE(PARTITION p BY ANY) IS ret_rec rec_type; BEGIN FOR rec IN p LOOP ret_rec.Ticker := rec.Ticker; ret_rec.PriceType := "O"; ret_rec.Price := rec.OpenPrice; PIPE ROW(ret_rec); ret_rec.Ticker := rec.Ticker; -- Redundant; not required ret_rec.PriceType := "C"; ret_rec.Price := rec.ClosePrice; push ret_rec; END LOOP; RETURN; END;
The function f can be used to generate another table from Stocks table in the following manner:
INSERT INTO AlternateStockTable SELECT * FROM TABLE(StockPivot(CURSOR(SELECT * FROM StockTable)));
If the StockTable is scanned in parallel and partitioned on OpenPrice, then the function StockPivot is combined with the data-flow operator doing the scan of StockTable and thus sees the same partitioning.
If, on the other hand, the StockTable is not partitioned, and the scan on it does not execute in parallel, the insert into AlternateStockTable also runs sequentially. Here is a slightly more complex example:
INSERT INTO AlternateStockTable
SELECT *
FROM TABLE(f(CURSOR(SELECT * FROM Stocks))),
TABLE(g(CURSOR( ... )))
WHERE join_condition;
where g is defined to be:
CREATE FUNCTION g(p refcur_pkg.refcur_t) RETURN ... PIPELINED PARALLEL_ENABLE (PARTITION p BY ANY) BEGIN ... END;
If function g runs in parallel and is partitioned by ANY, then the parallel insert can belong in the same data-flow operator as g.
Whenever the ANY keyword is specified, the data is partitioned randomly among the slaves. This effectively means that the function is executed in the same slave set which does the scan associated with the input parameter.
No redistribution or repartitioning of the data is required here. If the cursor p itself is not parallelized, the incoming data is randomly partitioned on the columns in the column list. The round-robin table queue is used for this partitioning.
To use parallel execution with a function that produces multiple rows, but does not need to accept multiple rows as input and so does not require a REF CURSOR, arrange things so as to create a need for a REF CURSOR. That way, the function will have some way to partition the work.
For example, suppose that you want a function to read a set of external files in parallel and return the records they contain. To provide work for a REF CURSOR, you might first create a table and populate it with the filenames. A REF CURSOR over this table can then be passed as a parameter to the table function (readfiles). The following code shows how this might be done:
CREATE TABLE filetab(filename VARCHAR(20)); INSERT INTO filetab VALUES('file0'); INSERT INTO filetab VALUES('file1'); ... INSERT INTO filetab VALUES('fileN'); SELECT * FROM TABLE(readfiles(CURSOR(SELECT filename FROM filetab))); CREATE FUNCTION readfiles(p pkg.rc_t) RETURN coll_type PARALLEL_ENABLE(PARTITION p BY ANY) IS ret_rec rec_type; BEGIN FOR rec IN p LOOP done := FALSE; WHILE (done = FALSE) LOOP done := readfilerecord(rec.filename, ret_rec); PIPE ROW(ret_rec); END LOOP; END LOOP; RETURN; END;
The way in which a table function orders or clusters rows that it fetches from cursor arguments is called data streaming. A function can stream its input data in any of the following ways:
Clustering causes rows that have the same key values to appear together but does not otherwise do any ordering of rows.
You control the behavior of the input stream using the ORDER BY or CLUSTER BY clauses when defining the function.
Input streaming can be specified for either sequential or parallel execution of a function.
If an ORDER BY or CLUSTER BY clause is not specified, rows are input in a (random) order.
The following example illustrates the syntax for ordering the input stream. In the example, function f takes in rows of the kind (Region, Sales) and returns rows of the form (Region, AvgSales), showing average sales for each region.
CREATE FUNCTION f(pref_cursor_type) RETURNtab_rec_typePIPELINED CLUSTER p BY Region PARALLEL_ENABLE(PARTITION p BY Region) IS ret_rec rec_type; cnt number; sum number; BEGIN FOR rec IN p LOOP IF (first rec in the group) THEN cnt := 1; sum := rec.Sales; ELSIF (last rec in the group) THEN IF (cnt <> 0) THEN ret_rec.Region := rec.Region; ret_rec.AvgSales := sum/cnt; PIPE ROW(ret_rec); END IF; ELSE cnt := cnt + 1; sum := sum + rec.Sales; END IF; END LOOP; RETURN; END;
Partitioning and clustering are easily confused, but they do different things. For example, sometimes partitioning can be sufficient without clustering in parallel execution.
Consider a function SmallAggr that performs in-memory aggregation of salary for each department_id, where department_id can be either 1, 2, or 3. The input rows to the function can be partitioned by HASH on department_id such that all rows with department_id equal to 1 go to one slave, all rows with department_id equal to 2 go to another slave, and so on.
The input rows do not need to be clustered on department_id to perform the aggregation in the function. Each slave could have a 1x3 array SmallSum[1..3] in which the aggregate sum for each department_id is added in memory into SmallSum[department_id]. On the other hand, if the number of unique values of department_id were very large, you would want to use clustering to compute department aggregates and write them to disk one department_id at a time.
By default, stored procedures and SQL methods execute with the privileges of their owner, not their current user. Such definer-rights subprograms are bound to the schema in which they reside. For example, assume that dept tables reside in schemas scott and blake, and that the following standalone procedure resides in schema scott:
CREATE PROCEDURE create_dept ( my_deptno NUMBER, my_dname VARCHAR2, my_loc VARCHAR2) AS BEGIN INSERT INTO dept VALUES (my_deptno, my_dname, my_loc); END;
Also assume that user scott has granted the EXECUTE privilege on this procedure to user blake. When user blake calls the procedure, the INSERT statement executes with the privileges of user scott. Also, the unqualified references to table dept is resolved in schema scott. So, even though user blake called the procedure, it updates the dept table in schema scott.
How can subprograms in one schema manipulate objects in another schema? One way is to fully qualify references to the objects, as in
INSERT INTO blake.dept ...
However, that hampers portability. As a workaround, you can define the schema name as a variable in SQL*Plus.
Another way is to copy the subprograms into the other schema. However, that hampers maintenance.
A better way is to use the AUTHID clause, which enables stored procedures and SQL methods to execute with the privileges and schema context of their current user.
Such invoker-rights subprograms are not bound to a particular schema. They can be run by a variety of users. The following version of procedure create_dept executes with the privileges of its current user and inserts rows into the dept table in that user's schema:
CREATE PROCEDURE create_dept ( my_deptno NUMBER, my_dname VARCHAR2, my_loc VARCHAR2) AUTHID CURRENT_USER AS BEGIN INSERT INTO dept VALUES (my_deptno, my_dname, my_loc); END;
Invoker-rights subprograms let you reuse code and centralize application logic. They are especially useful in applications that store data in different schemas. In such cases, multiple users can manage their own data using a single code base.
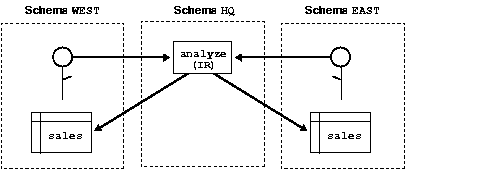
Consider a company that uses a definer-rights (DR) procedure to analyze sales. To provide local sales statistics, procedure analyze must access sales tables that reside at each regional site. So, as Figure 8-4 shows, the procedure must also reside at each regional site. This causes a maintenance problem.
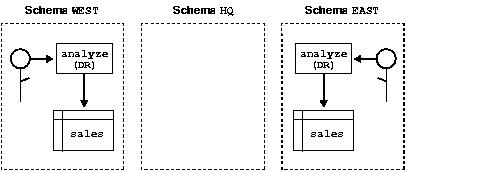
To solve the problem, the company installs an invoker-rights (IR) version of procedure analyze at headquarters. Now, as Figure 8-5 shows, all regional sites can use the same procedure to query their own sales tables.
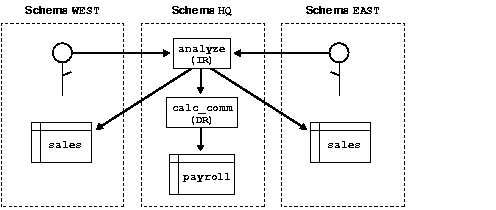
To restrict access to sensitive data, you can have an invoker-rights subprogram call a definer-rights subprogram. Suppose headquarters would like procedure analyze to calculate sales commissions and update a central payroll table.
That presents a problem because current users of analyze should not have direct access to the payroll table, which stores employee salaries and other sensitive data. As Figure 8-6 shows, the solution is to have procedure analyze call definer-rights procedure calc_comm, which in turn updates the payroll table.
To implement invoker rights, use the AUTHID clause, which specifies whether a subprogram executes with the privileges of its owner or its current user. It also specifies whether external references (that is, references to objects outside the subprogram) are resolved in the schema of the owner or the current user.
The AUTHID clause is allowed only in the header of a standalone subprogram, a package spec, or an object type spec. The header syntax is
-- standalone function CREATE [OR REPLACE] FUNCTION [schema_name.]function_name [(parameter_list)] RETURN datatype [AUTHID {CURRENT_USER | DEFINER}] {IS | AS} -- standalone procedure CREATE [OR REPLACE] PROCEDURE [schema_name.]procedure_name [(parameter_list)] [AUTHID {CURRENT_USER | DEFINER}] {IS | AS} -- package spec CREATE [OR REPLACE] PACKAGE [schema_name.]package_name [AUTHID {CURRENT_USER | DEFINER}] {IS | AS} -- object type spec CREATE [OR REPLACE] TYPE [schema_name.]object_type_name [AUTHID {CURRENT_USER | DEFINER}] {IS | AS} OBJECT
where DEFINER is the default option. In a package or object type, the AUTHID clause applies to all subprograms.
Note: Most supplied PL/SQL packages (such as DBMS_LOB, DBMS_PIPE, DBMS_ROWID, DBMS_SQL, and UTL_REF) are invoker-rights packages.
In a sequence of calls, if an invoker-rights subprogram is the first subprogram called, the current user is the session user. That remains true until a definer-rights subprogram is called, in which case the owner of that subprogram becomes the current user. If the definer-rights subprogram calls any invoker-rights subprograms, they execute with the privileges of the owner. When the definer-rights subprogram exits, control reverts to the previous current user.
If you specify AUTHID CURRENT_USER, the privileges of the current user are checked at run time, and external references are resolved in the schema of the current user. However, this applies only to external references in:
SELECT, INSERT, UPDATE, and DELETE data manipulation statementsLOCK TABLE transaction control statementOPEN and OPEN-FOR cursor control statementsEXECUTE IMMEDIATE and OPEN-FOR-USING dynamic SQL statementsDBMS_SQL.PARSE()For all other statements, the privileges of the owner are checked at compile time, and external references are resolved in the schema of the owner. For example, the assignment statement below refers to the packaged function balance. This external reference is resolved in the schema of the owner of procedure reconcile.
CREATE PROCEDURE reconcile (acc_id IN INTEGER) AUTHID CURRENT_USER AS bal NUMBER; BEGIN bal := bank_ops.balance(acct_id); ... END;
External references in an invoker-rights subprogram are resolved in the schema of the current user at run time. However, the PL/SQL compiler must resolve all references at compile time. So, the owner must create template objects in his or her schema beforehand. At run time, the template objects and the actual objects must match. Otherwise, you get an error or unexpected results.
For example, suppose user scott creates the following database table and standalone procedure:
CREATE TABLE emp ( empno NUMBER(4), ename VARCHAR2(15)); / CREATE PROCEDURE evaluate (my_empno NUMBER) AUTHID CURRENT_USER AS my_ename VARCHAR2(15); BEGIN SELECT ename INTO my_ename FROM emp WHERE empno = my_empno; ... END; /
Now, suppose user blake creates a similar database table, then calls procedure evaluate, as follows:
CREATE TABLE emp ( empno NUMBER(4), ename VARCHAR2(15), my_empno NUMBER(4)); -- note extra column / DECLARE ... BEGIN ... scott.evaluate(7788); END; /
The procedure call executes without error but ignores column my_empno in the table created by user blake. That is because the actual table in the schema of the current user does not match the template table used at compile time.
Occasionally, you might want to override the default invoker-rights behavior. Suppose user scott defines the standalone procedure below. Notice that the SELECT statement calls an external function. Normally, this external reference would be resolved in the schema of the current user.
CREATE PROCEDURE calc_bonus (emp_id INTEGER) AUTHID CURRENT_USER AS mid_sal REAL; BEGIN SELECT median(sal) INTO mid_sal FROM emp; ... END;
To have the reference resolved in the schema of the owner, create a public synonym for the function using the CREATE SYNONYM statement, as follows:
CREATE PUBLIC SYNONYM median FOR scott.median;
This works unless the current user has defined a function or private synonym named median. Alternatively, you can fully qualify the reference, as follows:
BEGIN SELECT scott.median(sal) INTO mid_sal FROM emp; ... END;
This works unless the current user has defined a package named scott that contains a function named median.
To call a subprogram directly, users must have the EXECUTE privilege on that subprogram. By granting the privilege, you allow a user to:
For external references resolved in the current user's schema (such as those in DML statements), the current user must have the privileges needed to access schema objects referenced by the subprogram. For all other external references (such as function calls), the owner's privileges are checked at compile time, and no run-time check is done.
A definer-rights subprogram operates under the security domain of its owner, no matter who is executing it. So, the owner must have the privileges needed to access schema objects referenced by the subprogram.
You can write a program consisting of multiple subprograms, some with definer rights and others with invoker rights. Then, you can use the EXECUTE privilege to restrict program entry points (controlled step-in). That way, users of an entry-point subprogram can execute the other subprograms indirectly but not directly.
Suppose user util grants the EXECUTE privilege on subprogram fft to user app, as follows:
GRANT EXECUTE ON util.fft TO app;
Now, user app can compile functions and procedures that call subprogram fft. At run time, no privilege checks on the calls are done. So, as Figure 8-7 shows, user util need not grant the EXECUTE privilege to every user who might call fft indirectly.
Notice that subprogram util.fft is called directly only from invoker-rights subprogram app.entry. So, user util must grant the EXECUTE privilege only to user app. When util.fft is executed, its current user could be app, scott, or blake even though scott and blake were not granted the EXECUTE privilege.
The use of roles in a subprogram depends on whether it executes with definer rights or invoker rights. Within a definer-rights subprogram, all roles are disabled. Roles are not used for privilege checking, and you cannot set roles.
Within an invoker-rights subprogram, roles are enabled (unless the subprogram was called directly or indirectly by a definer-rights subprogram). Roles are used for privilege checking, and you can use native dynamic SQL to set roles for the session. However, you cannot use roles to grant privileges on template objects because roles apply at run time, not at compile time.
For invoker-rights subprograms executed within a view expression, the view owner, not the view user, is considered to be the current user. For example, suppose user scott creates a view as shown below. The invoker-rights function layout always executes with the privileges of user scott, who is the view owner.
CREATE VIEW payroll AS SELECT layout(3) FROM dual;
This rule also applies to database triggers.
Invoker rights affect only one kind of database link--current-user links, which are created as follows:
CREATE DATABASE LINK link_name CONNECT TO CURRENT_USER USING connect_string;
A current-user link lets you connect to a remote database as another user, with that user's privileges. To connect, Oracle uses the username of the current user (who must be a global user). Suppose an invoker-rights subprogram owned by user blake references the database link below. If global user scott calls the subprogram, it connects to the Dallas database as user scott, who is the current user.
CREATE DATABASE LINK dallas CONNECT TO CURRENT_USER USING ...
If it were a definer-rights subprogram, the current user would be blake. So, the subprogram would connect to the Dallas database as global user blake.
To define object types for use in any schema, specify the AUTHID CURRENT_USER clause. (For more information about object types, see Chapter 10.) Suppose user blake creates the following object type:
CREATE TYPE Num AUTHID CURRENT_USER AS OBJECT ( x NUMBER, STATIC PROCEDURE new_num ( n NUMBER, schema_name VARCHAR2, table_name VARCHAR2) ); CREATE TYPE BODY Num AS STATIC PROCEDURE new_num ( n NUMBER, schema_name VARCHAR2, table_name VARCHAR2) IS sql_stmt VARCHAR2(200); BEGIN sql_stmt := 'INSERT INTO ' || schema_name || '.' || table_name || ' VALUES (blake.Num(:1))'; EXECUTE IMMEDIATE sql_stmt USING n; END; END;
Then, user blake grants the EXECUTE privilege on object type Num to user scott:
GRANT EXECUTE ON Num TO scott;
Finally, user scott creates an object table to store objects of type Num, then calls procedure new_num to populate the table:
CONNECT scott/tiger; CREATE TABLE num_tab OF blake.Num; / BEGIN blake.Num.new_num(1001, 'scott', 'num_tab'); blake.Num.new_num(1002, 'scott', 'num_tab'); blake.Num.new_num(1003, 'scott', 'num_tab'); END; /
The calls succeed because the procedure executes with the privileges of its current user (scott), not its owner (blake).
For subtypes in an object type hierarchy, the following rules apply:
AUTHID clause, it inherits the AUTHID of its supertype.AUTHID clause, its AUTHID must match the AUTHID of its supertype. Also, if the AUTHID is DEFINER, both the supertype and subtype must have been created in the same schema.An invoker-rights instance method executes with the privileges of the invoker, not the creator of the instance. Suppose that Person is an invoker-rights object type, and that user scott creates p1, an object of type Person. If user blake calls instance method change_job to operate on object p1, the current user of the method is blake, not scott. Consider the following example:
-- user blake creates a definer-rights procedure CREATE PROCEDURE reassign (p Person, new_job VARCHAR2) AS BEGIN -- user blake calls method change_job, so the -- method executes with the privileges of blake p.change_job(new_job); ... END; -- user scott passes a Person object to the procedure DECLARE p1 Person; BEGIN p1 := Person(...); blake.reassign(p1, 'CLERK'); ... END;
Recursion is a powerful technique for simplifying the design of algorithms. Basically, recursion means self-reference. In a recursive mathematical sequence, each term is derived by applying a formula to preceding terms. The Fibonacci sequence (0, 1, 1, 2, 3, 5, 8, 13, 21, ...), which was first used to model the growth of a rabbit colony, is an example. Each term in the sequence (after the second) is the sum of the two terms that immediately precede it.
In a recursive definition, something is defined as simpler versions of itself. Consider the definition of n factorial (n!), the product of all integers from 1 to n:
n! = n * (n - 1)!
A recursive subprogram is one that calls itself. Think of a recursive call as a call to some other subprogram that does the same task as your subprogram. Each recursive call creates a new instance of any items declared in the subprogram, including parameters, variables, cursors, and exceptions. Likewise, new instances of SQL statements are created at each level in the recursive descent.
Be careful where you place a recursive call. If you place it inside a cursor FOR loop or between OPEN and CLOSE statements, another cursor is opened at each call. As a result, your program might exceed the limit set by the Oracle initialization parameter OPEN_CURSORS.
There must be at least two paths through a recursive subprogram: one that leads to the recursive call and one that does not. At least one path must lead to a terminating condition. Otherwise, the recursion would (theoretically) go on forever. In practice, if a recursive subprogram strays into infinite regress, PL/SQL eventually runs out of memory and raises the predefined exception STORAGE_ERROR.
To solve some programming problems, you must repeat a sequence of statements until a condition is met. You can use iteration or recursion to solve such problems. Use recursion when the problem can be broken down into simpler versions of itself. For example, you can evaluate 3! as follows:
0! = 1 -- by definition 1! = 1 * 0! = 1 2! = 2 * 1! = 2 3! = 3 * 2! = 6
To implement this algorithm, you might write the following recursive function, which returns the factorial of a positive integer:
FUNCTION fac (n POSITIVE) RETURN INTEGER IS -- returns n! BEGIN IF n = 1 THEN -- terminating condition RETURN 1; ELSE RETURN n * fac(n - 1); -- recursive call END IF; END fac;
At each recursive call, n is decremented. Eventually, n becomes 1 and the recursion stops.
Consider the procedure below, which finds the staff of a given manager. The procedure declares two formal parameters, mgr_no and tier, which represent the manager's employee number and a tier in his or her departmental organization. Staff members reporting directly to the manager occupy the first tier.
PROCEDURE find_staff (mgr_no NUMBER, tier NUMBER := 1) IS boss_name VARCHAR2(10); CURSOR c1 (boss_no NUMBER) IS SELECT empno, ename FROM emp WHERE mgr = boss_no; BEGIN /* Get manager's name. */ SELECT ename INTO boss_name FROM emp WHERE empno = mgr_no; IF tier = 1 THEN INSERT INTO staff -- single-column output table VALUES (boss_name || ' manages the staff'); END IF; /* Find staff members who report directly to manager. */ FOR ee IN c1 (mgr_no) LOOP INSERT INTO staff VALUES (boss_name || ' manages ' || ee.ename || ' on tier ' || TO_CHAR(tier)); /* Drop to next tier in organization. */ find_staff(ee.empno, tier + 1); -- recursive call END LOOP; COMMIT; END;
When called, the procedure accepts a value for mgr_no but uses the default value of tier. For example, you might call the procedure as follows:
find_staff(7839);
The procedure passes mgr_no to a cursor in a cursor FOR loop, which finds staff members at successively lower tiers in the organization. At each recursive call, a new instance of the FOR loop is created and another cursor is opened, but prior cursors stay positioned on the next row in their result sets.
When a fetch fails to return a row, the cursor is closed automatically and the FOR loop is exited. Since the recursive call is inside the FOR loop, the recursion stops. Unlike the initial call, each recursive call passes a second actual parameter (the next tier) to the procedure.
The last example illustrates recursion, not the efficient use of set-oriented SQL statements. You might want to compare the performance of the recursive procedure to that of the following SQL statement, which does the same task:
INSERT INTO staff SELECT PRIOR ename || ' manages ' || ename || ' on tier ' || TO_CHAR(LEVEL - 1) FROM emp START WITH empno = 7839 CONNECT BY PRIOR empno = mgr;
The SQL statement is appreciably faster. However, the procedure is more flexible. For example, a multi-table query cannot contain the CONNECT BY clause. So, unlike the procedure, the SQL statement cannot be modified to do joins. (A join combines rows from two or more database tables.) In addition, a procedure can process data in ways that a single SQL statement cannot.
Subprograms are mutually recursive if they directly or indirectly call each other. In the example below, the Boolean functions odd and even, which determine whether a number is odd or even, call each other directly. The forward declaration of odd is necessary because even calls odd, which is not yet declared when the call is made.
FUNCTION odd (n NATURAL) RETURN BOOLEAN; -- forward declaration FUNCTION even (n NATURAL) RETURN BOOLEAN IS BEGIN IF n = 0 THEN RETURN TRUE; ELSE RETURN odd(n - 1); -- mutually recursive call END IF; END even; FUNCTION odd (n NATURAL) RETURN BOOLEAN IS BEGIN IF n = 0 THEN RETURN FALSE; ELSE RETURN even(n - 1); -- mutually recursive call END IF; END odd;
When a positive integer n is passed to odd or even, the functions call each other by turns. At each call, n is decremented. Ultimately, n becomes zero and the final call returns TRUE or FALSE. For instance, passing the number 4 to odd results in this sequence of calls:
odd(4) even(3) odd(2) even(1) odd(0) -- returns FALSE
On the other hand, passing the number 4 to even results in this sequence of calls:
even(4) odd(3) even(2) odd(1) even(0) -- returns TRUE
Unlike iteration, recursion is not essential to PL/SQL programming. Any problem that can be solved using recursion can be solved using iteration. Also, the iterative version of a subprogram is usually easier to design than the recursive version. However, the recursive version is usually simpler, smaller, and therefore easier to debug. Compare the following functions, which compute the nth Fibonacci number:
-- recursive version FUNCTION fib (n POSITIVE) RETURN INTEGER IS BEGIN IF (n = 1) OR (n = 2) THEN RETURN 1; ELSE RETURN fib(n - 1) + fib(n - 2); END IF; END fib; -- iterative version FUNCTION fib (n POSITIVE) RETURN INTEGER IS pos1 INTEGER := 1; pos2 INTEGER := 0; accumulator INTEGER; BEGIN IF (n = 1) OR (n = 2) THEN RETURN 1; ELSE accumulator := pos1 + pos2; FOR i IN 3..n LOOP pos2 := pos1; pos1 := accumulator; accumulator := pos1 + pos2; END LOOP; RETURN accumulator; END IF; END fib;
The recursive version of fib is more elegant than the iterative version. However, the iterative version is more efficient; it runs faster and uses less storage. That is because each recursive call requires additional time and memory. As the number of recursive calls gets larger, so does the difference in efficiency. Still, if you expect the number of recursive calls to be small, you might choose the recursive version for its readability.
PL/SQL is a powerful development tool; you can use it for almost any purpose. However, it is specialized for SQL transaction processing. So, some tasks are more quickly done in a lower-level language such as C, which is very efficient at machine-precision calculations. Other tasks are more easily done in a fully object-oriented, standardized language such as Java.
To support such special-purpose processing, you can use PL/SQL call specs to invoke external subprograms (that is, subprograms written in other languages). This makes the strengths and capabilities of those languages available to you from PL/SQL.
For example, you can call Java stored procedures from any PL/SQL block, subprogram, or package. Suppose you store the following Java class in the database:
import java.sql.*; import oracle.jdbc.driver.*; public class Adjuster { public static void raiseSalary (int empNo, float percent) throws SQLException { Connection conn = new OracleDriver().defaultConnection(); String sql = "UPDATE emp SET sal = sal * ? WHERE empno = ?"; try { PreparedStatement pstmt = conn.prepareStatement(sql); pstmt.setFloat(1, (1 + percent / 100)); pstmt.setInt(2, empNo); pstmt.executeUpdate(); pstmt.close(); } catch (SQLException e) {System.err.println(e.getMessage());} } }
The class Adjuster has one method, which raises the salary of an employee by a given percentage. Because raiseSalary is a void method, you publish it as a procedure using this call spec:
CREATE PROCEDURE raise_salary (empno NUMBER, pct NUMBER) AS LANGUAGE JAVA NAME 'Adjuster.raiseSalary(int, float)';
Later, you might call procedure raise_salary from an anonymous PL/SQL block, as follows:
DECLARE emp_id NUMBER; percent NUMBER; BEGIN -- get values for emp_id and percent raise_salary(emp_id, percent); -- call external subprogram
Typically, external C subprograms are used to interface with embedded systems, solve engineering problems, analyze data, or control real-time devices and processes. External C subprograms let you extend the functionality of the database server, and move computation-bound programs from client to server, where they execute faster.
For more information about Java stored procedures, see Oracle9i Java Stored Procedures Developer's Guide. For more information about external C subprograms, see Oracle9i Application Developer's Guide - Fundamentals.
PL/SQL Server Pages (PSPs) enable you to develop Web pages with dynamic content. They are an alternative to coding a stored procedure that writes out the HTML code for a web page, one line at a time.
Using special tags, you can embed PL/SQL scripts into HTML source code. The scripts are executed when the pages are requested by Web clients such as browsers. A script can accept parameters, query or update the database, then display a customized page showing the results.
During development, PSPs can act like templates with a static part for page layout and a dynamic part for content. You can design the layouts using your favorite HTML authoring tools, leaving placeholders for the dynamic content. Then, you can write the PL/SQL scripts that generate the content. When finished, you simply load the resulting PSP files into the database as stored procedures.
For more information about creating and using PSPs, see Oracle9i Application Developer's Guide - Fundamentals.
|
 Copyright © 1996, 2002 Oracle Corporation. All Rights Reserved. |
|

