Release 2 (9.2)
Part Number A96601-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Real Application Clusters Real Application Clusters Guard I - Concepts and Administration Release 2 (9.2) Part Number A96601-01 |
|
This chapter describes how to administer an Oracle Real Application Clusters Guard environment. It includes the following sections:
This section contains the following topics:
Maintenance, such as hardware repair or an operating system upgrade, requires a planned outage so that the primary role can be moved to the secondary node. Plan it for a part of the business cycle that is less busy and give advance notification to users. To administer a planned outage on the primary node, perform the following steps:
PFSCTL command line, enter the move_primary command to move the primary role to the secondary instance:
PFSCTL> move_primary
PFSCTL> restore
PFSCTL> switchover
Maintenance on the secondary node does not interrupt operation, but the system is not resilient while the secondary node is down. To administer a planned outage on the secondary node, perform the following steps:
PFSCTL> stop_secondary
PFSCTL> restore
When an unplanned outage occurs on the primary node, Oracle Real Application Clusters Guard automatically fails over to the secondary node and notifies the user that a role change has occurred. At this point, Oracle Real Application Clusters Guard is operating in a nonresilient state with the primary role on the former secondary node.
After you have performed root cause analysis and repaired the source of the fault, restore the secondary role on the former primary node by using the restore command:
PFSCTL> restore
The primary and secondary roles have now been reversed. Choose one of the following actions:
After restoring both packs, you can continue to operate with primary and secondary roles that are reversed from the initial state. For sites with symmetric configurations, there is no need to return to the original state. Returning to the original roles requires a planned outage and can be avoided. In fact, some users intentionally operate with role reversal on a fixed schedule (such as every three months) in order to test the capabilities of the system.
Returning to the original primary/secondary configuration requires a planned outage while the primary role is moved. Plan it for a less busy part of your business cycle and give advance notice to users. Execute it as follows:
# pfsctl PFSCTL> switchover
If your system includes more than one uniquely identified database on each node, then performance may be degraded after a failover. For example, if you have a two-node cluster in a primary/secondary configuration and you are also running an unrelated database on the secondary node, then the secondary node runs the primary services as well as the unrelated database after failover and may be overloaded. In this situation, you should move the less critical service to the other node when it is restored.
Perform the following steps for each of the services that are moved to the restored node:
ORACLE_SERVICE and DB_NAME environment variables. For example:
$ export ORACLE_SERVICE=SALES $ export DB_NAME=sales
# pfsctl PFSCTL> restore
PFSCTL> switchover
Figure 6-1 and Figure 6-2 show what happens when both instances of a two-node cluster fail.
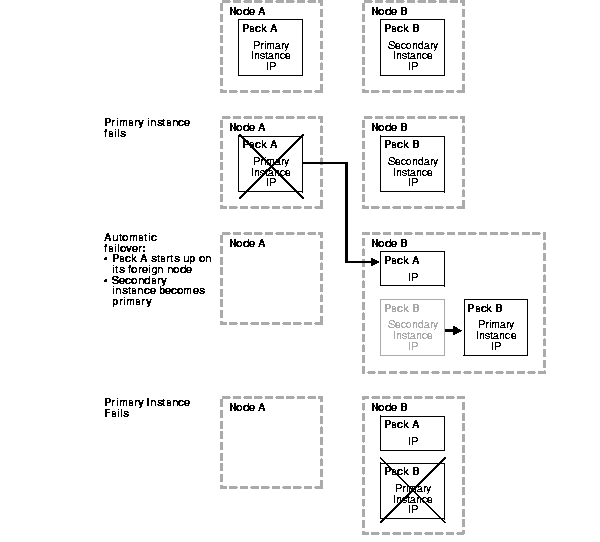
During normal operation, both Node A and Node B are up and operational. Pack A is running on its home node, Node A, and has the primary role. It contains the primary instance and an IP address. Pack B is running on its home node, Node B, and has the secondary role. It contains the secondary instance and an IP address.
If the primary instance fails, then Oracle Real Application Clusters Guard automatically takes the following failover actions:
Now both Pack A and Pack B are running on Node B. Pack B contains the primary instance and its IP address. Pack A contains only an IP address. Nothing is running on Node A. The system is not resilient.
If the primary instance fails, then Pack A and Pack B contain only IP addresses.
Figure 6-2 shows what happens after the primary instance fails.
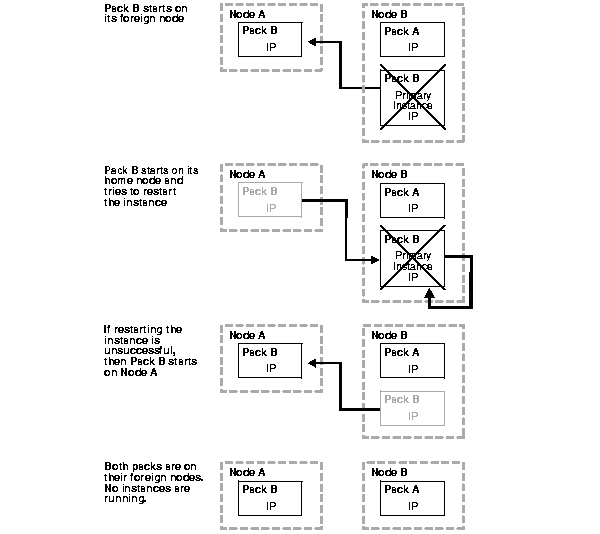
Pack B starts on its foreign node (Node A). Pack A is still running on Node B. Only the IP addresses are up on the nodes. Because there is no instance running, Pack B restarts on its home node and tries to restart the primary instance. If restarting the instance is unsuccessful, Pack B again starts on its foreign node. The outcome of double instance failure is:
Diagnose and repair the cause of the failures. To restart the instances, you must perform the following steps:
PFSCTL> pfshalt
You should see output similar to the following:
pfshalt command succeeded.
PFSCTL> pfsboot
You should see output similar to the following:
pfsboot command succeeded.
Oracle Real Application Clusters Guard restores service quickly. The application must restart transactions when it receives an Oracle message that indicates that failure has occurred.
Failing over the application when the primary instance fails is straightforward. The application sessions receive the ORA-1089 and ORA-1034 Oracle errors for new requests and the ORA-1041, ORA-3113, and ORA-3114 Oracle errors for active requests. These errors must be trapped by the application. At reconnection, the application connects transparently to the new primary instance. For example, in the case of a Web server, the server threads are restarted for each connection pool against the new primary instance. The current transactions are then resubmitted by the clients.
Failing over the application when the primary node fails is not straightforward because of TCP/IP time-out. TCP/IP time-out is a significant problem for high availability. It occurs when a node fails without closing the sockets, because new requests can be made to an IP address that is unavailable. For active requests, the delays to the client are the values for TCP_IP_ABORT_CINTERVAL and TCP_IP_ABORT_INTERVAL. For sessions that are waiting for read/write completion, the delay is the value for TCP_KEEPALIVE_INTERVAL. The values for these TCP/IP parameter should be tuned at each site.
|
Note: These parameters are specific to your operating system. See your operating system-specific documentation for more information. |
TCP/IP time-outs are addressed in Oracle Real Application Clusters Guard by using relocatable IP addresses and the call-home feature. Because Oracle Real Application Clusters Guard moves the IP addresses, active requests for an address do not wait to time out. Requests for connection are refused immediately and are routed transparently to the new primary instance. Requests that issue SQL statements receive a broken pipe error (ORA-3113), allowing the application to restart. The application should detect this error and take appropriate action.
The role change notification in Oracle Real Application Clusters Guard can enhance application failover. The feature allows you to implement actions such as running or halting applications when the notification of a role change (UP, PLANNED_UP, PLANNED_DOWN, DOWN, CLEANUP) is received. For example, when the instance starts, the notification can be used to start the applications. When the instance terminates, the notification can be used to halt the applications. It is also possible to halt the application when a role starts. This allows secondary applications to halt when the primary role fails over, for example.
Automatic role change notification behaves as follows:
UP notification occurs
DOWN notification occurs before the instance (primary or secondary) is shut downCLEANUP notification occurs after the instance (primary or secondary) is shut downManual role notification occurs only when PFSCTL commands are executed, for example, during planned outages. Manual role notification behaves as follows:
PLANNED_UP notification occurs before the instance (primary or secondary) startsPLANNED_DOWN notification occurs before the instance (primary or secondary) is shut down
Most configuration changes can be made to an Oracle Real Application Clusters Guard environment by switching over to the secondary instance, applying the change, and switching back (optional). The following types of configuration changes are described in this section:
There are several ways to change Oracle Real Application Clusters Guard configuration parameters, depending on what kind of parameter needs to be changed. For example, changing $ORACLE_HOME requires the packs to be re-created, while changing the port numbers requires that the packs, the database, and the listener be halted.
| See Also:
Chapter 3, "Oracle Real Application Clusters Guard Configuration Parameters" for information about changing configuration parameters |
To change initialization parameters for both instances, perform the following steps:
PFSCTL> stop_secondary
PFSCTL> restore
PFSCTL> move_primary
PFSCTL> restore
switchover command.)
| See Also:
Chapter 3, "Oracle Real Application Clusters Guard Configuration Parameters" for information about changing configuration parameters |
Oracle supports many online configuration changes.
SQL> ALTER SYSTEM SET fast_start_mttr_target = 120;
| See Also:
Oracle9i Database Reference to find out which initialization parameters can be changed online |
The PFS_KEEP_PRIMARY parameter specifies whether to leave the primary pack up and running when the secondary pack does not come up when the pfsboot command is entered.
Figure 6-3 shows the effect of entering the pfsboot command during normal operation.
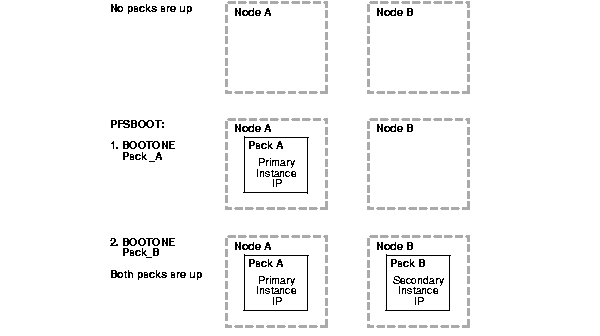
Before the command is entered, no packs are running. When the pfsboot command is entered, Oracle Real Application Clusters Guard first starts Pack A on Node A, which becomes the primary node. Then Oracle Real Application Clusters Guard starts Pack B on Node B, which becomes the secondary node.
Figure 6-4 shows what happens when PFS_KEEP_PRIMARY is set to $PFS_TRUE and the second pack does not start.
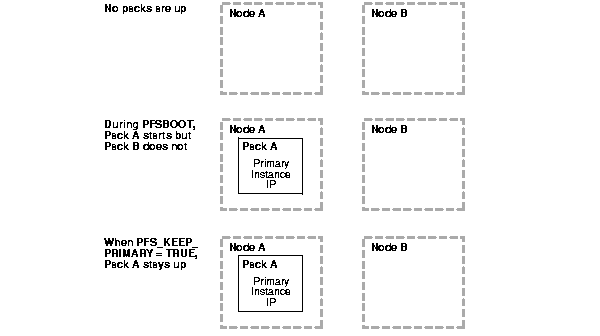
When the pfsboot command is entered, Oracle Real Application Clusters Guard starts Pack A on Node A, which becomes the primary node. However, when Oracle Real Application Clusters Guard tries to start Pack B on Node B, it fails for some reason. If PFS_KEEP_PRIMARY is set to $PFS_TRUE, then Pack A remains up. The system runs without resilience while you diagnose the cause of the failure on Node B.
Figure 6-5 shows what happens when PFS_KEEP_PRIMARY is set to $PFS_FALSE and the second pack does not start.
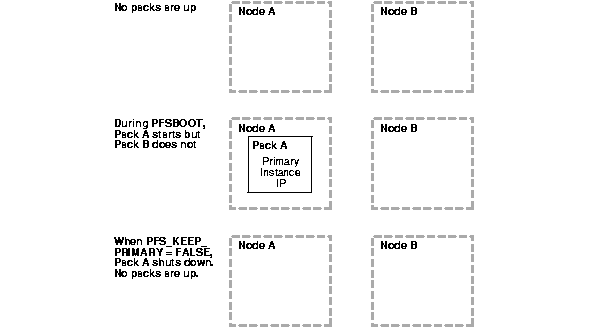
When the pfsboot command is entered, Oracle Real Application Clusters Guard starts Pack A on Node A, which becomes the primary node. If Oracle Real Application Clusters Guard fails to start Pack B on Node B and PFS_KEEP_PRIMARY is set to $PFS_FALSE, then Oracle Real Application Clusters Guard shuts down Pack A on Node A. No packs are running.
| See Also:
"Changing Oracle Real Application Clusters Guard Configuration Parameters" for more information about changing the value of the |
The heartbeat monitor uses a database table, ORAPING_CONFIG, to record the configuration information. The use of a table ensures that both instances of the cluster always use the same value. This table is refreshed on an interval defined by the CONFIG_INTERVAL parameter.
Table 6-1 shows the parameters in the ORAPING_CONFIG table.
Suppose performance issues arise during initial testing of the system. Then you can run Oracle Real Application Clusters Guard with the values in the ORAPING_CONFIG table raised to a level that allows problems to persist long enough for detailed analysis. You can lower the configuration values when the system is stable.
Another reason to change the values in the ORAPING_CONFIG table is to customize them for different workloads. False failovers can occur when workloads are so large that timeouts occur simply because the system is busy.
To change the values in the ORAPING_CONFIG table, perform steps similar to the following:
$ORACLE_USER and view the default values in the ORAPING_CONFIG table. Enter the following commands:
$ sqlplus / SQL> SELECT * FROM oraping_config;
You should see the following output:
INTERNAL_TIMEOUT USER_TIMEOUT MAX_RETRIES SPECIAL_WAIT RECOVERY_RAMPUP_TIME ---------------- ------------ ----------- ------------ -------------------- CYCLE_TIME CONNECT_TIMEOUT CONFIG_INTERVAL TRACE_FLAG TRACE_ITERATIONS ---------- --------------- --------------- ---------- ---------------- LOGON_STORM_THRESHOLD --------------------- 30 60 3 300 300 120 30 600 0 1 50
ORAPING_CONFIG table. Enter commands similar to the following:
SQL> UPDATE oraping_config SET 2 cycle_time = 300, 3 connect_timeout = 120, 4 user_timeout = 120, 5 special_wait = 600, 6 logon_storm_threshold =100; 1 row updated. SQL> COMMIT;
SQL> SELECT * FROM oraping_config;
You should see output similar to the following:
INTERNAL_TIMEOUT USER_TIMEOUT MAX_RETRIES SPECIAL_WAIT RECOVERY_RAMPUP_TIME ---------------- ------------ ----------- ------------ -------------------- CYCLE_TIME CONNECT_TIMEOUT CONFIG_INTERVAL TRACE_FLAG TRACE_ITERATIONS ---------- --------------- --------------- ---------- ---------------- LOGON_STORM_THRESHOLD --------------------- 30 120 3 600 300 300 120 600 0 1 100
|
Note: Do not delete the Oracle Real Application Clusters Guard log files. They are essential for tracking faults. |
Oracle Real Application Clusters Guard writes log files and debug files to the following locations:
$ORACLE_BASE/admin/$DB_NAME/pfs/pfsdump$ORACLE_HOME/pfs/$DB_NAME/log
To find the Oracle Real Application Clusters Guard logs, change to the pfsdump directory. Enter a command similar to the following:
$ cd /mnt1/oracle/admin/sales/pfs/pfsdump
List the contents of the directory. You should see output similar to the following:
pfs_sales_host1.debug pfs_sales_host1_ping.log pfs_sales_host1.log
Allow sufficient space for the log files. If the log files become too large, then copy them manually to a backup location. Oracle Real Application Clusters Guard automatically opens a new copy of the file that has been archived when it writes to the file again.
When datafiles are in backup mode, they appear to instance recovery as if they are past versions. Oracle issues a message at the next startup that says media recovery is required. Media recovery is not required. Solve the problem by taking the following actions:
The steps are shown in more detail as follows:
PFSCTL> pfshalt
$ sqlplus "system/manager as sysdba" SQL> startup mount;
SELECT file#, recover, fuzzy, tablespace_name, name FROM v$datafile_header WHERE fuzzy = 'YES' ;
You should see output similar to the following:
FILE# REC FUZ TABLESPACE NAME ----- --- --- ---------- --------------------------------- 6 NO YES USERS /dev/vx/rdsk/home-dg/oracle_usr01 7 NO YES USERS /dev/vx/rdsk/home-dg/oracle_usr02
SQL> ALTER DATABASE DATAFILE '/dev/vx/rdsk/home-dg/oracle_usr01' END BACKUP;
You should see output similar to the following:
Database altered.
Continue taking affected datafiles out of backup mode.
SQL> ALTER DATABASE DATAFILE '/dev/vx/rdsk/home-dg/oracle_usr02' END BACKUP; Database altered.
|
Note: If you repeat the |
SQL> ALTER DATABASE DATAFILE '/dev/vx/rdsk/home-dg/oracle_usr01' END BACKUP;
Output similar to the following may occur:
alter database datafile '/dev/vx/rdsk/home-dg/oracle_usr01' end backup * ERROR at line 1: ORA-01235: END BACKUP failed for 1 file(s) and succeeded for 0 ORA-01199: file 6 is not in online backup mode ORA-01110: data file 6: '/dev/vx/rdsk/home-dg/oracle_usr01'
SQL> shutdown immediate
PFSCTL> pfsboot
|
Note: You should also take datafiles out of backup mode before a switchover. You can do it manually, or you can implement it as a call-out from the |
|
 Copyright © 2001, 2002 Oracle Corporation. All Rights Reserved. |
|

