| Oracle9i Streams Release 2 (9.2) Part Number A96571-02 |
|





|
View PDF |
| Oracle9i Streams Release 2 (9.2) Part Number A96571-02 |
|
|
View PDF |
This chapter illustrates an example of a multiple source replication environment that can be constructed using Streams.
This chapter contains these topics:
This example illustrates using Streams to replicate data for a schema among three Oracle databases. DML and DDL changes made to tables in the hr schema are captured at all databases in the environment and propagated to each of the other databases in the environment.
Figure 23-1 provides an overview of the environment.
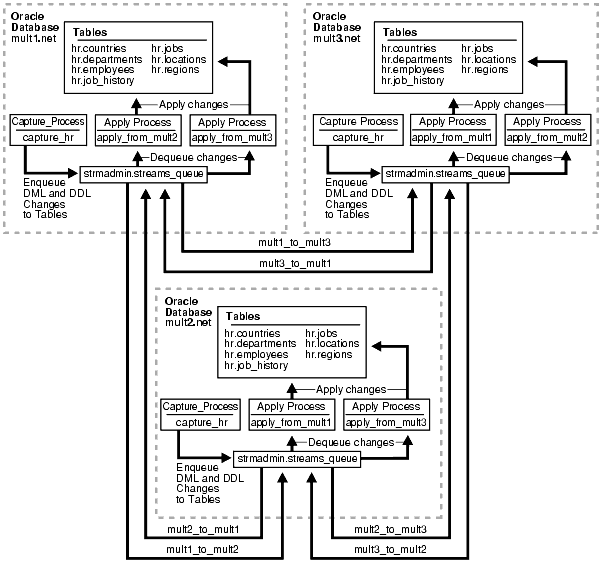
As illustrated in Figure 23-1, all of the databases will contain the hr schema when the example is complete. However, at the beginning of the example, the hr schema exists only at mult1.net. During the example, you instantiate the hr schema at mult2.net and mult3.net.
In this example, Streams is used to perform the following series of actions:
hr schema and enqueues them into a local queue.hr schema received from the other databases in the environment.This example uses only one queue for each database, but you can use multiple queues for each database if you want to separate changes from different source databases. In addition, this example avoids sending changes back to their source database by using the default apply tag for the apply processes. When you create an apply process, the changes applied by the apply process have redo entries with a tag of '00' (double zero) by default. These changes are not recaptured because, by default, rules created by the DBMS_STREAMS_ADM package have an is_null_tag()='Y' condition by default, and this condition ensures that each capture process captures a change in a redo entry only if the tag for the redo entry is NULL.
| See Also:
Oracle9i Streams for more information about tags |
The following prerequisites must be completed before you begin the example in this chapter.
AQ_TM_PROCESSES: This parameter establishes queue monitor processes. Values from 1 to 10 specify the number of queue monitor processes created to monitor the messages. If AQ_TM_PROCESSES is not specified or is set to 0, then the queue monitor processes are not created. In this example, AQ_TM_PROCESSES should be set to at least 1.
Setting the parameter to 1 or more starts the specified number of queue monitor processes. These queue monitor processes are responsible for managing time-based operations of messages such as delay and expiration, cleaning up retained messages after the specified retention time, and cleaning up consumed messages if the retention time is 0.
GLOBAL_NAMES: This parameter must be set to true. Make sure the global names of the databases are mult1.net, mult2.net, and mult3.net.JOB_QUEUE_PROCESSES: This parameter must be set to at least 2 because each database propagates events. It should be set to the same value as the maximum number of jobs that can run simultaneously plus one.COMPATIBLE: This parameter must be set to 9.2.0 or higher.LOG_PARALLELISM: This parameter must be set to 1 because each database that captures events.
|
Attention: You may need to modify other initialization parameter settings for this example to run properly. |
| See Also:
"Setting Initialization Parameters Relevant to Streams" for information about other initialization parameters that are important in a Streams environment |
ARCHIVELOG mode. In this example, all databases are capturing changes, and so all databases must be running in ARCHIVELOG mode.
| See Also:
Oracle9i Database Administrator's Guide for information about running a database in |
This section illustrates how to set up users and create queues and database links for a Streams replication environment that includes three Oracle databases. The remaining parts of this example depend on the users and queues that you configure in this section.
Complete the following steps to set up the users and to create the streams_queue at all of the databases.
/************************* BEGINNING OF SCRIPT ******************************
Run SET ECHO ON and specify the spool file for the script. Check the spool file for errors after you run this script.
*/ SET ECHO ON SPOOL streams_setup_mult.out /*
Connect to mult1.net as the hr user.
*/ CONNECT hr/hr@mult1.net /*
Convert the hr.countries table from an index-organized table to a regular table. Currently, the capture process cannot capture changes to index-organized tables.
*/ ALTER TABLE countries RENAME TO countries_orig; CREATE TABLE hr.countries( country_id CHAR(2) CONSTRAINT country_id_nn_noiot NOT NULL, country_name VARCHAR2(40), region_id NUMBER, CONSTRAINT country_c_id_pk_noiot PRIMARY KEY (country_id)); ALTER TABLE hr.countries ADD (CONSTRAINT countr_reg_fk_noiot FOREIGN KEY (region_id) REFERENCES regions(region_id)); INSERT INTO COUNTRIES (SELECT * FROM hr.countries_orig); DROP TABLE hr.countries_orig CASCADE CONSTRAINTS; ALTER TABLE locations ADD (CONSTRAINT loc_c_id_fk FOREIGN KEY (country_id) REFERENCES countries(country_id)); /*
By default, the LogMiner tables are in the SYSTEM tablespace, but the SYSTEM tablespace may not have enough space for these tables once a capture process starts to capture changes. Therefore, you must create an alternate tablespace for the LogMiner tables.
Connect to mult1.net as SYS user.
*/ CONNECT SYS/CHANGE_ON_INSTALL@mult1.net AS SYSDBA /*
Create an alternate tablespace for the LogMiner tables.
*/ ACCEPT tspace_name DEFAULT 'logmnrts' PROMPT 'Enter the name of the tablespace (for example, logmnrts): ' ACCEPT db_file_directory DEFAULT '' PROMPT 'Enter the complete path to the datafile directory (for example, /usr/oracle/dbs): ' ACCEPT db_file_name DEFAULT 'logmnrts.dbf' PROMPT 'Enter the name of the datafile (for example, logmnrts.dbf): ' CREATE TABLESPACE &tspace_name DATAFILE '&db_file_directory/&db_file_name' SIZE 25 M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED; EXECUTE DBMS_LOGMNR_D.SET_TABLESPACE('&tspace_name'); /*
Create the Streams administrator named strmadmin and grant this user the necessary privileges. These privileges enable the user to manage queues, execute subprograms in packages related to Streams, create rule sets, create rules, and monitor the Streams environment by querying data dictionary views and queue tables. You may choose a different name for this user.
*/ GRANT CONNECT, RESOURCE, SELECT_CATALOG_ROLE TO strmadmin IDENTIFIED BY strmadminpw; ACCEPT streams_tbs PROMPT 'Enter Streams administrator tablespace on mult1.net: ' ALTER USER strmadmin DEFAULT TABLESPACE &streams_tbs QUOTA UNLIMITED ON &streams_tbs; GRANT EXECUTE ON DBMS_APPLY_ADM TO strmadmin; GRANT EXECUTE ON DBMS_AQADM TO strmadmin; GRANT EXECUTE ON DBMS_CAPTURE_ADM TO strmadmin; GRANT EXECUTE ON DBMS_PROPAGATION_ADM TO strmadmin; GRANT EXECUTE ON DBMS_STREAMS_ADM TO strmadmin; BEGIN DBMS_RULE_ADM.GRANT_SYSTEM_PRIVILEGE( privilege => DBMS_RULE_ADM.CREATE_RULE_SET_OBJ, grantee => 'strmadmin', grant_option => FALSE); END; / BEGIN DBMS_RULE_ADM.GRANT_SYSTEM_PRIVILEGE( privilege => DBMS_RULE_ADM.CREATE_RULE_OBJ, grantee => 'strmadmin', grant_option => FALSE); END; / /*
Connect as the Streams administrator at mult1.net.
*/ CONNECT strmadmin/strmadminpw@mult1.net /*
Run the SET_UP_QUEUE procedure to create a queue named streams_queue at mult1.net. This queue will function as the Streams queue by holding the changes that will be applied at this database and the changes that will be propagated to other databases.
Running the SET_UP_QUEUE procedure performs the following actions:
streams_queue_table. This queue table is owned by the Streams administrator (strmadmin) and uses the default storage of this user.streams_queue owned by the Streams administrator (strmadmin).*/ EXEC DBMS_STREAMS_ADM.SET_UP_QUEUE(); /*
Create database links from the current database to the other databases in the environment.
*/ CREATE DATABASE LINK mult2.net CONNECT TO strmadmin IDENTIFIED BY strmadminpw USING 'mult2.net'; CREATE DATABASE LINK mult3.net CONNECT TO strmadmin IDENTIFIED BY strmadminpw USING 'mult3.net'; /*
This example will configure the tables in the hr schema for conflict resolution based on the latest time for a transaction.
Connect to mult1.net as the hr user.
*/ CONNECT hr/hr@mult1.net /*
Add a time column to each table in the hr schema.
*/ ALTER TABLE hr.countries ADD (time TIMESTAMP WITH TIME ZONE); ALTER TABLE hr.departments ADD (time TIMESTAMP WITH TIME ZONE); ALTER TABLE hr.employees ADD (time TIMESTAMP WITH TIME ZONE); ALTER TABLE hr.job_history ADD (time TIMESTAMP WITH TIME ZONE); ALTER TABLE hr.jobs ADD (time TIMESTAMP WITH TIME ZONE); ALTER TABLE hr.locations ADD (time TIMESTAMP WITH TIME ZONE); ALTER TABLE hr.regions ADD (time TIMESTAMP WITH TIME ZONE); /*
Create a trigger for each table in the hr schema to insert the time of a transaction for each row inserted or updated by the transaction.
*/ CREATE OR REPLACE TRIGGER hr.insert_time_countries BEFORE INSERT OR UPDATE ON hr.countries FOR EACH ROW BEGIN -- Consider time synchronization problems. The previous update to this -- row may have originated from a site with a clock time ahead of the -- local clock time. IF :OLD.TIME IS NULL OR :OLD.TIME < SYSTIMESTAMP THEN :NEW.TIME := SYSTIMESTAMP; ELSE :NEW.TIME := :OLD.TIME + 1 / 86400; END IF; END; / CREATE OR REPLACE TRIGGER hr.insert_time_departments BEFORE INSERT OR UPDATE ON hr.departments FOR EACH ROW BEGIN IF :OLD.TIME IS NULL OR :OLD.TIME < SYSTIMESTAMP THEN :NEW.TIME := SYSTIMESTAMP; ELSE :NEW.TIME := :OLD.TIME + 1 / 86400; END IF; END; / CREATE OR REPLACE TRIGGER hr.insert_time_employees BEFORE INSERT OR UPDATE ON hr.employees FOR EACH ROW BEGIN IF :OLD.TIME IS NULL OR :OLD.TIME < SYSTIMESTAMP THEN :NEW.TIME := SYSTIMESTAMP; ELSE :NEW.TIME := :OLD.TIME + 1 / 86400; END IF; END; / CREATE OR REPLACE TRIGGER hr.insert_time_job_history BEFORE INSERT OR UPDATE ON hr.job_history FOR EACH ROW BEGIN IF :OLD.TIME IS NULL OR :OLD.TIME < SYSTIMESTAMP THEN :NEW.TIME := SYSTIMESTAMP; ELSE :NEW.TIME := :OLD.TIME + 1 / 86400; END IF; END; / CREATE OR REPLACE TRIGGER hr.insert_time_jobs BEFORE INSERT OR UPDATE ON hr.jobs FOR EACH ROW BEGIN IF :OLD.TIME IS NULL OR :OLD.TIME < SYSTIMESTAMP THEN :NEW.TIME := SYSTIMESTAMP; ELSE :NEW.TIME := :OLD.TIME + 1 / 86400; END IF; END; / CREATE OR REPLACE TRIGGER hr.insert_time_locations BEFORE INSERT OR UPDATE ON hr.locations FOR EACH ROW BEGIN IF :OLD.TIME IS NULL OR :OLD.TIME < SYSTIMESTAMP THEN :NEW.TIME := SYSTIMESTAMP; ELSE :NEW.TIME := :OLD.TIME + 1 / 86400; END IF; END; / CREATE OR REPLACE TRIGGER hr.insert_time_regions BEFORE INSERT OR UPDATE ON hr.regions FOR EACH ROW BEGIN IF :OLD.TIME IS NULL OR :OLD.TIME < SYSTIMESTAMP THEN :NEW.TIME := SYSTIMESTAMP; ELSE :NEW.TIME := :OLD.TIME + 1 / 86400; END IF; END; / /*
By default, the LogMiner tables are in the SYSTEM tablespace, but the SYSTEM tablespace may not have enough space for these tables once a capture process starts to capture changes. Therefore, you must create an alternate tablespace for the LogMiner tables.
Connect to mult2.net as SYS user.
*/ CONNECT SYS/CHANGE_ON_INSTALL@mult2.net AS SYSDBA /*
Create an alternate tablespace for the LogMiner tables.
*/ ACCEPT tspace_name DEFAULT 'logmnrts' PROMPT 'Enter the name of the tablespace (for example, logmnrts): ' ACCEPT db_file_directory DEFAULT '' PROMPT 'Enter the complete path to the datafile directory (for example, /usr/oracle/dbs): ' ACCEPT db_file_name DEFAULT 'logmnrts.dbf' PROMPT 'Enter the name of the datafile (for example, logmnrts.dbf): ' CREATE TABLESPACE &tspace_name DATAFILE '&db_file_directory/&db_file_name' SIZE 25 M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED; EXECUTE DBMS_LOGMNR_D.SET_TABLESPACE('&tspace_name'); /*
Create the Streams administrator named strmadmin and grant this user the necessary privileges. These privileges enable the user to manage queues, execute subprograms in packages related to Streams, create rule sets, create rules, and monitor the Streams environment by querying data dictionary views and queue tables. You may choose a different name for this user.
*/ GRANT CONNECT, RESOURCE, SELECT_CATALOG_ROLE TO strmadmin IDENTIFIED BY strmadminpw; ACCEPT streams_tbs PROMPT 'Enter Streams administrator tablespace on mult2.net: ' ALTER USER strmadmin DEFAULT TABLESPACE &streams_tbs QUOTA UNLIMITED ON &streams_tbs; GRANT EXECUTE ON DBMS_APPLY_ADM TO strmadmin; GRANT EXECUTE ON DBMS_AQADM TO strmadmin; GRANT EXECUTE ON DBMS_CAPTURE_ADM TO strmadmin; GRANT EXECUTE ON DBMS_FLASHBACK TO strmadmin; GRANT EXECUTE ON DBMS_PROPAGATION_ADM TO strmadmin; GRANT EXECUTE ON DBMS_STREAMS_ADM TO strmadmin; BEGIN DBMS_RULE_ADM.GRANT_SYSTEM_PRIVILEGE( privilege => DBMS_RULE_ADM.CREATE_RULE_SET_OBJ, grantee => 'strmadmin', grant_option => FALSE); END; / BEGIN DBMS_RULE_ADM.GRANT_SYSTEM_PRIVILEGE( privilege => DBMS_RULE_ADM.CREATE_RULE_OBJ, grantee => 'strmadmin', grant_option => FALSE); END; / /*
Connect as the Streams administrator at mult2.net.
*/ CONNECT strmadmin/strmadminpw@mult2.net /*
Run the SET_UP_QUEUE procedure to create a queue named streams_queue at mult2.net. This queue will function as the Streams queue by holding the changes that will be applied at this database and the changes that will be propagated to other databases.
Running the SET_UP_QUEUE procedure performs the following actions:
streams_queue_table. This queue table is owned by the Streams administrator (strmadmin) and uses the default storage of this user.streams_queue owned by the Streams administrator (strmadmin).*/ EXEC DBMS_STREAMS_ADM.SET_UP_QUEUE(); /*
Create database links from the current database to the other databases in the environment.
*/ CREATE DATABASE LINK mult1.net CONNECT TO strmadmin IDENTIFIED BY strmadminpw USING 'mult1.net'; CREATE DATABASE LINK mult3.net CONNECT TO strmadmin IDENTIFIED BY strmadminpw USING 'mult3.net'; /*
This example illustrates instantiating the tables in the hr schema at mult2.net by exporting these tables from mult1.net and importing them into mult2.net. You must drop the tables in the hr schema at mult2.net for the instantiation portion of this example to work properly.
Connect as hr at mult2.net.
*/ CONNECT hr/hr@mult2.net /*
Drop all tables in the hr schema in the mult2.net database.
*/ DROP TABLE hr.countries CASCADE CONSTRAINTS; DROP TABLE hr.departments CASCADE CONSTRAINTS; DROP TABLE hr.employees CASCADE CONSTRAINTS; DROP TABLE hr.job_history CASCADE CONSTRAINTS; DROP TABLE hr.jobs CASCADE CONSTRAINTS; DROP TABLE hr.locations CASCADE CONSTRAINTS; DROP TABLE hr.regions CASCADE CONSTRAINTS; /*
By default, the LogMiner tables are in the SYSTEM tablespace, but the SYSTEM tablespace may not have enough space for these tables once a capture process starts to capture changes. Therefore, you must create an alternate tablespace for the LogMiner tables.
Connect to mult3.net as SYS user.
*/ CONNECT SYS/CHANGE_ON_INSTALL@mult3.net AS SYSDBA /*
Create an alternate tablespace for the LogMiner tables.
*/ ACCEPT tspace_name DEFAULT 'logmnrts' PROMPT 'Enter the name of the tablespace (for example, logmnrts): ' ACCEPT db_file_directory DEFAULT '' PROMPT 'Enter the complete path to the datafile directory (for example, /usr/oracle/dbs): ' ACCEPT db_file_name DEFAULT 'logmnrts.dbf' PROMPT 'Enter the name of the datafile (for example, logmnrts.dbf): ' CREATE TABLESPACE &tspace_name DATAFILE '&db_file_directory/&db_file_name' SIZE 25 M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED; EXECUTE DBMS_LOGMNR_D.SET_TABLESPACE('&tspace_name'); /*
Create the Streams administrator named strmadmin and grant this user the necessary privileges. These privileges enable the user to manage queues, execute subprograms in packages related to Streams, create rule sets, create rules, and monitor the Streams environment by querying data dictionary views and queue tables. You may choose a different name for this user.
*/ GRANT CONNECT, RESOURCE, SELECT_CATALOG_ROLE TO strmadmin IDENTIFIED BY strmadminpw; ACCEPT streams_tbs PROMPT 'Enter Streams administrator tablespace on mult3.net: ' ALTER USER strmadmin DEFAULT TABLESPACE &streams_tbs QUOTA UNLIMITED ON &streams_tbs; GRANT EXECUTE ON DBMS_APPLY_ADM TO strmadmin; GRANT EXECUTE ON DBMS_AQADM TO strmadmin; GRANT EXECUTE ON DBMS_CAPTURE_ADM TO strmadmin; GRANT EXECUTE ON DBMS_FLASHBACK TO strmadmin; GRANT EXECUTE ON DBMS_PROPAGATION_ADM TO strmadmin; GRANT EXECUTE ON DBMS_STREAMS_ADM TO strmadmin; BEGIN DBMS_RULE_ADM.GRANT_SYSTEM_PRIVILEGE( privilege => DBMS_RULE_ADM.CREATE_RULE_SET_OBJ, grantee => 'strmadmin', grant_option => FALSE); END; / BEGIN DBMS_RULE_ADM.GRANT_SYSTEM_PRIVILEGE( privilege => DBMS_RULE_ADM.CREATE_RULE_OBJ, grantee => 'strmadmin', grant_option => FALSE); END; / /*
Connect as the Streams administrator at mult3.net.
*/ CONNECT strmadmin/strmadminpw@mult3.net /*
Run the SET_UP_QUEUE procedure to create a queue named streams_queue at mult3.net. This queue will function as the Streams queue by holding the changes that will be applied at this database and the changes that will be propagated to other databases.
Running the SET_UP_QUEUE procedure performs the following actions:
streams_queue_table. This queue table is owned by the Streams administrator (strmadmin) and uses the default storage of this user.streams_queue owned by the Streams administrator (strmadmin).*/ EXEC DBMS_STREAMS_ADM.SET_UP_QUEUE(); /*
Create database links from the current database to the other databases in the environment.
*/ CREATE DATABASE LINK mult1.net CONNECT TO strmadmin IDENTIFIED BY strmadminpw USING 'mult1.net'; CREATE DATABASE LINK mult2.net CONNECT TO strmadmin IDENTIFIED BY strmadminpw USING 'mult2.net'; /*
This example illustrates instantiating the tables in the hr schema at mult3.net by exporting these tables from mult1.net and importing them into mult3.net. You must drop the tables in the hr schema at mult3.net for the instantiation portion of this example to work properly.
Connect as hr at mult3.net.
*/ CONNECT hr/hr@mult3.net /*
Drop all tables in the hr schema in the mult3.net database.
*/ DROP TABLE hr.countries CASCADE CONSTRAINTS; DROP TABLE hr.departments CASCADE CONSTRAINTS; DROP TABLE hr.employees CASCADE CONSTRAINTS; DROP TABLE hr.job_history CASCADE CONSTRAINTS; DROP TABLE hr.jobs CASCADE CONSTRAINTS; DROP TABLE hr.locations CASCADE CONSTRAINTS; DROP TABLE hr.regions CASCADE CONSTRAINTS; /*
Check the streams_setup_mult.out spool file to ensure that all actions finished successfully after this script is completed.
*/ SET ECHO OFF SPOOL OFF /*************************** END OF SCRIPT ******************************/
Complete the following steps to configure a Streams environment that shares information from multiple databases.
/************************* BEGINNING OF SCRIPT ******************************
Run SET ECHO ON and specify the spool file for the script. Check the spool file for errors after you run this script.
*/ SET ECHO ON SPOOL streams_mult.out /*
Connect to mult1.net as SYS user.
*/ CONNECT SYS/CHANGE_ON_INSTALL@mult1.net AS SYSDBA /*
Specify an unconditional supplemental log group that includes the primary key for each table and the column list for each table, as specified in "Configure Latest Time Conflict Resolution at mult1.net".
*/ ALTER TABLE hr.countries ADD SUPPLEMENTAL LOG GROUP log_group_countries (country_id, country_name, region_id, time) ALWAYS; ALTER TABLE hr.departments ADD SUPPLEMENTAL LOG GROUP log_group_departments (department_id, department_name, manager_id, location_id, time) ALWAYS; ALTER TABLE hr.employees ADD SUPPLEMENTAL LOG GROUP log_group_employees (employee_id, first_name, last_name, email, phone_number, hire_date, job_id, salary, commission_pct, manager_id, department_id, time) ALWAYS; ALTER TABLE hr.jobs ADD SUPPLEMENTAL LOG GROUP log_group_jobs (job_id, job_title, min_salary, max_salary, time) ALWAYS; ALTER TABLE hr.job_history ADD SUPPLEMENTAL LOG GROUP log_group_job_history (employee_id, start_date, end_date, job_id, department_id, time) ALWAYS; ALTER TABLE hr.locations ADD SUPPLEMENTAL LOG GROUP log_group_locations (location_id, street_address, postal_code, city, state_province, country_id, time) ALWAYS; ALTER TABLE hr.regions ADD SUPPLEMENTAL LOG GROUP log_group_regions (region_id, region_name, time) ALWAYS; /*
Connect to mult1.net as the strmadmin user.
*/ CONNECT strmadmin/strmadminpw@mult1.net /*
Create the capture process to capture changes to the entire hr schema at mult1.net. After this step is complete, users can modify tables in the hr schema at mult1.net.
*/ BEGIN DBMS_STREAMS_ADM.ADD_SCHEMA_RULES( schema_name => 'hr', streams_type => 'capture', streams_name => 'capture_hr', queue_name => 'strmadmin.streams_queue', include_dml => true, include_ddl => true); END; / /*
Configure mult1.net to apply changes to the hr schema at mult2.net.
*/ BEGIN DBMS_STREAMS_ADM.ADD_SCHEMA_RULES( schema_name => 'hr', streams_type => 'apply', streams_name => 'apply_from_mult2', queue_name => 'strmadmin.streams_queue', include_dml => true, include_ddl => true, source_database => 'mult2.net'); END; / /*
Configure mult1.net to apply changes to the hr schema at mult3.net.
*/ BEGIN DBMS_STREAMS_ADM.ADD_SCHEMA_RULES( schema_name => 'hr', streams_type => 'apply', streams_name => 'apply_from_mult3', queue_name => 'strmadmin.streams_queue', include_dml => true, include_ddl => true, source_database => 'mult3.net'); END; / /*
In this example, the hr user owns all of the database objects for which changes are applied by the apply process at this database. Therefore, hr already has the necessary privileges to change these database objects, and it is convenient to make hr the apply user.
When the apply process was created in the previous step, the Streams administrator strmadmin was specified as the apply user by default, because strmadmin ran the procedure that created the apply process. Instead of specifying hr as the apply user, you could retain strmadmin as the apply user, but then you must grant strmadmin privileges on all of the database objects for which changes are applied and privileges to execute all user procedures used by the apply process. In an environment where an apply process applies changes to database objects in multiple schemas, it may be more convenient to use the Streams administrator as the apply user.
*/ BEGIN DBMS_APPLY_ADM.ALTER_APPLY( apply_name => 'apply_from_mult2', apply_user => 'hr'); END; / BEGIN DBMS_APPLY_ADM.ALTER_APPLY( apply_name => 'apply_from_mult3', apply_user => 'hr'); END; / /*
Because the hr user was specified as the apply user in the previous step, the hr user requires execute privilege on the rule set used by each apply process
*/ DECLARE rs_name VARCHAR2(64); -- Variable to hold rule set name BEGIN SELECT RULE_SET_OWNER||'.'||RULE_SET_NAME INTO rs_name FROM DBA_APPLY WHERE APPLY_NAME='APPLY_FROM_MULT2'; DBMS_RULE_ADM.GRANT_OBJECT_PRIVILEGE( privilege => SYS.DBMS_RULE_ADM.EXECUTE_ON_RULE_SET, object_name => rs_name, grantee => 'hr'); END; / DECLARE rs_name VARCHAR2(64); -- Variable to hold rule set name BEGIN SELECT RULE_SET_OWNER||'.'||RULE_SET_NAME INTO rs_name FROM DBA_APPLY WHERE APPLY_NAME='APPLY_FROM_MULT3'; DBMS_RULE_ADM.GRANT_OBJECT_PRIVILEGE( privilege => SYS.DBMS_RULE_ADM.EXECUTE_ON_RULE_SET, object_name => rs_name, grantee => 'hr'); END; / /*
Specify an update conflict handler for each table in the hr schema. For each table, designate the time column as the resolution column for a MAXIMUM conflict handler. When an update conflict occurs, such an update conflict handler applies the transaction with the latest (or greater) time and discards the transaction with the earlier (or lesser) time. The column lists for each table do not include the primary key because this example assumes that primary key values are never updated.
*/ DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'country_name'; cols(2) := 'region_id'; cols(3) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.countries', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; / DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'department_name'; cols(2) := 'manager_id'; cols(3) := 'location_id'; cols(4) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.departments', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; / DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'first_name'; cols(2) := 'last_name'; cols(3) := 'email'; cols(4) := 'phone_number'; cols(5) := 'hire_date'; cols(6) := 'job_id'; cols(7) := 'salary'; cols(8) := 'commission_pct'; cols(9) := 'manager_id'; cols(10) := 'department_id'; cols(11) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.employees', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; / DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'job_title'; cols(2) := 'min_salary'; cols(3) := 'max_salary'; cols(4) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.jobs', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; / DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'employee_id'; cols(2) := 'start_date'; cols(3) := 'end_date'; cols(4) := 'job_id'; cols(5) := 'department_id'; cols(6) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.job_history', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; / DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'street_address'; cols(2) := 'postal_code'; cols(3) := 'city'; cols(4) := 'state_province'; cols(5) := 'country_id'; cols(6) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.locations', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; / DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'region_name'; cols(2) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.regions', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; / /*
Configure and schedule propagation of DML and DDL changes in the hr schema from the queue at mult1.net to the queue at mult2.net.
*/ BEGIN DBMS_STREAMS_ADM.ADD_SCHEMA_PROPAGATION_RULES( schema_name => 'hr', streams_name => 'mult1_to_mult2', source_queue_name => 'strmadmin.streams_queue', destination_queue_name => 'strmadmin.streams_queue@mult2.net', include_dml => true, include_ddl => true, source_database => 'mult1.net'); END; / /*
Configure and schedule propagation of DML and DDL changes in the hr schema from the queue at mult1.net to the queue at mult3.net.
*/ BEGIN DBMS_STREAMS_ADM.ADD_SCHEMA_PROPAGATION_RULES( schema_name => 'hr', streams_name => 'mult1_to_mult3', source_queue_name => 'strmadmin.streams_queue', destination_queue_name => 'strmadmin.streams_queue@mult3.net', include_dml => true, include_ddl => true, source_database => 'mult1.net'); END; / /*
Connect to mult2.net as the strmadmin user.
*/ CONNECT strmadmin/strmadminpw@mult2.net /*
Create the capture process to capture changes to the entire hr schema at mult2.net.
*/ BEGIN DBMS_STREAMS_ADM.ADD_SCHEMA_RULES( schema_name => 'hr', streams_type => 'capture', streams_name => 'capture_hr', queue_name => 'strmadmin.streams_queue', include_dml => true, include_ddl => true); END; / /*
In this example, the hr schema already exists at all of the databases. The tables in the schema exist only at mult1.net until they are instantiated at mult2.net and mult3.net in Step 21. The instantiation is done using an export of the tables from mult1.net. These export/import operations set the schema instantiation SCNs for mult1.net at mult2.net and mult3.net automatically.
However, the instantiation SCNs for mult2.net and mult3.net are not set automatically at the other sites in the environment. This step sets the schema instantiation SCN for mult2.net manually at mult1.net and mult3.net. The current SCN at mult2.net is obtained by using the GET_SYSTEM_CHANGE_NUMBER function in the DBMS_FLASHBACK package at mult2.net. This SCN is used at mult1.net and mult3.net to run the SET_SCHEMA_INSTANTIATION_SCN procedure in the DBMS_APPLY_ADM package.
The SET_SCHEMA_INSTANTIATION_SCN procedure controls which DDL LCRs for a schema are ignored by an apply process and which DDL LCRs for a schema are applied by an apply process. If the commit SCN of a DDL LCR for a database object in a schema from a source database is less than or equal to the instantiation SCN for that database object at some destination database, then the apply process at the destination database disregards the DDL LCR. Otherwise, the apply process applies the DDL LCR.
Because you are running the SET_SCHEMA_INSTANTIATION_SCN procedure before the tables are instantiated at mult2.net, and because the local capture process is configured already, you do not need to run the SET_TABLE_INSTANTIATION_SCN for each table after the instantiation. In this example, an apply process at both mult1.net and mult3.net will apply transactions to the tables in the hr schema with SCNs that were committed after the SCN obtained in this step.
*/ DECLARE iscn NUMBER; -- Variable to hold instantiation SCN value BEGIN iscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER(); DBMS_APPLY_ADM.SET_SCHEMA_INSTANTIATION_SCN@MULT1.NET( source_schema_name => 'hr', source_database_name => 'mult2.net', instantiation_scn => iscn); DBMS_APPLY_ADM.SET_SCHEMA_INSTANTIATION_SCN@MULT3.NET( source_schema_name => 'hr', source_database_name => 'mult2.net', instantiation_scn => iscn); END; /
/*
Configure mult2.net to apply changes to the hr schema at mult1.net.
*/ BEGIN DBMS_STREAMS_ADM.ADD_SCHEMA_RULES( schema_name => 'hr', streams_type => 'apply', streams_name => 'apply_from_mult1', queue_name => 'strmadmin.streams_queue', include_dml => true, include_ddl => true, source_database => 'mult1.net'); END; / /*
Configure mult2.net to apply changes to the hr schema at mult3.net.
*/ BEGIN DBMS_STREAMS_ADM.ADD_SCHEMA_RULES( schema_name => 'hr', streams_type => 'apply', streams_name => 'apply_from_mult3', queue_name => 'strmadmin.streams_queue', include_dml => true, include_ddl => true, source_database => 'mult3.net'); END; / /*
In this example, the hr user owns all of the database objects for which changes are applied by the apply process at this database. Therefore, hr already has the necessary privileges to change these database objects, and it is convenient to make hr the apply user.
When the apply process was created in the previous step, the Streams administrator strmadmin was specified as the apply user by default, because strmadmin ran the procedure that created the apply process. Instead of specifying hr as the apply user, you could retain strmadmin as the apply user, but then you must grant strmadmin privileges on all of the database objects for which changes are applied and privileges to execute all user procedures used by the apply process. In an environment where an apply process applies changes to database objects in multiple schemas, it may be more convenient to use the Streams administrator as the apply user.
*/ BEGIN DBMS_APPLY_ADM.ALTER_APPLY( apply_name => 'apply_from_mult1', apply_user => 'hr'); END; / BEGIN DBMS_APPLY_ADM.ALTER_APPLY( apply_name => 'apply_from_mult3', apply_user => 'hr'); END; / /*
Because the hr user was specified as the apply user in the previous step, the hr user requires execute privilege on the rule set used by each apply process
*/ DECLARE rs_name VARCHAR2(64); -- Variable to hold rule set name BEGIN SELECT RULE_SET_OWNER||'.'||RULE_SET_NAME INTO rs_name FROM DBA_APPLY WHERE APPLY_NAME='APPLY_FROM_MULT1'; DBMS_RULE_ADM.GRANT_OBJECT_PRIVILEGE( privilege => SYS.DBMS_RULE_ADM.EXECUTE_ON_RULE_SET, object_name => rs_name, grantee => 'hr'); END; / DECLARE rs_name VARCHAR2(64); -- Variable to hold rule set name BEGIN SELECT RULE_SET_OWNER||'.'||RULE_SET_NAME INTO rs_name FROM DBA_APPLY WHERE APPLY_NAME='APPLY_FROM_MULT3'; DBMS_RULE_ADM.GRANT_OBJECT_PRIVILEGE( privilege => SYS.DBMS_RULE_ADM.EXECUTE_ON_RULE_SET, object_name => rs_name, grantee => 'hr'); END; / /*
Configure and schedule propagation of DML and DDL changes in the hr schema from the queue at mult2.net to the queue at mult1.net.
*/ BEGIN DBMS_STREAMS_ADM.ADD_SCHEMA_PROPAGATION_RULES( schema_name => 'hr', streams_name => 'mult2_to_mult1', source_queue_name => 'strmadmin.streams_queue', destination_queue_name => 'strmadmin.streams_queue@mult1.net', include_dml => true, include_ddl => true, source_database => 'mult2.net'); END; / /*
Configure and schedule propagation of DML and DDL changes in the hr schema from the queue at mult2.net to the queue at mult3.net.
*/ BEGIN DBMS_STREAMS_ADM.ADD_SCHEMA_PROPAGATION_RULES( schema_name => 'hr', streams_name => 'mult2_to_mult3', source_queue_name => 'strmadmin.streams_queue', destination_queue_name => 'strmadmin.streams_queue@mult3.net', include_dml => true, include_ddl => true, source_database => 'mult2.net'); END; / /*
Connect to mult3.net as the strmadmin user.
*/ CONNECT strmadmin/strmadminpw@mult3.net /*
Create the capture process to capture changes to the entire hr schema at mult3.net.
*/ BEGIN DBMS_STREAMS_ADM.ADD_SCHEMA_RULES( schema_name => 'hr', streams_type => 'capture', streams_name => 'capture_hr', queue_name => 'strmadmin.streams_queue', include_dml => true, include_ddl => true); END; / /*
In this example, the hr schema already exists at all of the databases. The tables in the schema exist only at mult1.net until they are instantiated at mult2.net and mult3.net in Step 21. The instantiation is done using an export of the tables from mult1.net. These export/import operations set the schema instantiation SCNs for mult1.net at mult2.net and mult3.net automatically.
However, the instantiation SCNs for mult2.net and mult3.net are not set automatically at the other sites in the environment. This step sets the schema instantiation SCN for mult3.net manually at mult1.net and mult2.net. The current SCN at mult3.net is obtained by using the GET_SYSTEM_CHANGE_NUMBER function in the DBMS_FLASHBACK package at mult3.net. This SCN is used at mult1.net and mult2.net to run the SET_SCHEMA_INSTANTIATION_SCN procedure in the DBMS_APPLY_ADM package.
The SET_SCHEMA_INSTANTIATION_SCN procedure controls which DDL LCRs for a schema are ignored by an apply process and which DDL LCRs for a schema are applied by an apply process. If the commit SCN of a DDL LCR for a database object in a schema from a source database is less than or equal to the instantiation SCN for that database object at some destination database, then the apply process at the destination database disregards the DDL LCR. Otherwise, the apply process applies the DDL LCR.
Because you are running the SET_SCHEMA_INSTANTIATION_SCN procedure before the tables are instantiated at mult3.net, and because the local capture process is configured already, you do not need to run the SET_TABLE_INSTANTIATION_SCN for each table after the instantiation. In this example, an apply process at both mult1.net and mult2.net will apply transactions to the tables in the hr schema with SCNs that were committed after the SCN obtained in this step.
*/ DECLARE iscn NUMBER; -- Variable to hold instantiation SCN value BEGIN iscn := DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER(); DBMS_APPLY_ADM.SET_SCHEMA_INSTANTIATION_SCN@MULT1.NET( source_schema_name => 'hr', source_database_name => 'mult3.net', instantiation_scn => iscn); DBMS_APPLY_ADM.SET_SCHEMA_INSTANTIATION_SCN@MULT2.NET( source_schema_name => 'hr', source_database_name => 'mult3.net', instantiation_scn => iscn); END; / /*
Configure mult3.net to apply changes to the hr schema at mult1.net.
*/ BEGIN DBMS_STREAMS_ADM.ADD_SCHEMA_RULES( schema_name => 'hr', streams_type => 'apply', streams_name => 'apply_from_mult1', queue_name => 'strmadmin.streams_queue', include_dml => true, include_ddl => true, source_database => 'mult1.net'); END; / /*
Configure mult3.net to apply changes to the hr schema at mult2.net.
*/ BEGIN DBMS_STREAMS_ADM.ADD_SCHEMA_RULES( schema_name => 'hr', streams_type => 'apply', streams_name => 'apply_from_mult2', queue_name => 'strmadmin.streams_queue', include_dml => true, include_ddl => true, source_database => 'mult2.net'); END; / /*
In this example, the hr user owns all of the database objects for which changes are applied by the apply process at this database. Therefore, hr already has the necessary privileges to change these database objects, and it is convenient to make hr the apply user.
When the apply process was created in the previous step, the Streams administrator strmadmin was specified as the apply user by default, because strmadmin ran the procedure that created the apply process. Instead of specifying hr as the apply user, you could retain strmadmin as the apply user, but then you must grant strmadmin privileges on all of the database objects for which changes are applied and privileges to execute all user procedures used by the apply process. In an environment where an apply process applies changes to database objects in multiple schemas, it may be more convenient to use the Streams administrator as the apply user.
*/ BEGIN DBMS_APPLY_ADM.ALTER_APPLY( apply_name => 'apply_from_mult1', apply_user => 'hr'); END; / BEGIN DBMS_APPLY_ADM.ALTER_APPLY( apply_name => 'apply_from_mult2', apply_user => 'hr'); END; / /*
Because the hr user was specified as the apply user in the previous step, the hr user requires execute privilege on the rule set used by each apply process
*/ DECLARE rs_name VARCHAR2(64); -- Variable to hold rule set name BEGIN SELECT RULE_SET_OWNER||'.'||RULE_SET_NAME INTO rs_name FROM DBA_APPLY WHERE APPLY_NAME='APPLY_FROM_MULT1'; DBMS_RULE_ADM.GRANT_OBJECT_PRIVILEGE( privilege => SYS.DBMS_RULE_ADM.EXECUTE_ON_RULE_SET, object_name => rs_name, grantee => 'hr'); END; / DECLARE rs_name VARCHAR2(64); -- Variable to hold rule set name BEGIN SELECT RULE_SET_OWNER||'.'||RULE_SET_NAME INTO rs_name FROM DBA_APPLY WHERE APPLY_NAME='APPLY_FROM_MULT2'; DBMS_RULE_ADM.GRANT_OBJECT_PRIVILEGE( privilege => SYS.DBMS_RULE_ADM.EXECUTE_ON_RULE_SET, object_name => rs_name, grantee => 'hr'); END; / /*
Configure and schedule propagation of DML and DDL changes in the hr schema from the queue at mult3.net to the queue at mult1.net.
*/ BEGIN DBMS_STREAMS_ADM.ADD_SCHEMA_PROPAGATION_RULES( schema_name => 'hr', streams_name => 'mult3_to_mult1', source_queue_name => 'strmadmin.streams_queue', destination_queue_name => 'strmadmin.streams_queue@mult1.net', include_dml => true, include_ddl => true, source_database => 'mult3.net'); END; / /*
Configure and schedule propagation of DML and DDL changes in the hr schema from the queue at mult3.net to the queue at mult2.net.
*/ BEGIN DBMS_STREAMS_ADM.ADD_SCHEMA_PROPAGATION_RULES( schema_name => 'hr', streams_name => 'mult3_to_mult2', source_queue_name => 'strmadmin.streams_queue', destination_queue_name => 'strmadmin.streams_queue@mult2.net', include_dml => true, include_ddl => true, source_database => 'mult3.net'); END; / /*
Open a different window and export the schema at mult1.net that will be instantiated at mult2.net and mult3.net. Make sure you set the OBJECT_CONSISTENT export parameter to y when you run the export command. Also, make sure no DDL changes are made to the objects being exported during the export.
The following is an example export command:
exp hr/hr FILE=hr_schema.dmp OWNER=hr OBJECT_CONSISTENT=y
| See Also:
Oracle9i Database Utilities for information about performing an export |
*/ PAUSE Press <RETURN> to continue when the export is complete in the other window that you opened. /*
Transfer the export dump file hr_schema.dmp to the destination databases. In this example, the destination databases are mult2.net and mult3.net.
You can use binary FTP or some other method to transfer the export dump file to the destination database. You may need to open a different window to transfer the file.
*/ PAUSE Press <RETURN> to continue after transferring the dump file to all of the other databases in the environment. /*
In a different window, connect to the computer that runs the mult2.net database and import the export dump file hr_schema.dmp to instantiate the tables in the mult2.net database. You can use telnet or remote login to connect to the computer that runs mult2.net.
When you run the import command, make sure you set the STREAMS_INSTANTIATION import parameter to y. This parameter ensures that the import records export SCN information for each object imported.
Also, make sure no changes are made to the tables in the schema being imported at the destination database (mult2.net) until the import is complete and the capture process is created.
The following is an example import command:
imp hr/hr FILE=hr_schema.dmp FROMUSER=hr IGNORE=y COMMIT=y LOG=import.log STREAMS_INSTANTIATION=y
| See Also:
Oracle9i Database Utilities for information about performing an import |
*/ PAUSE Press <RETURN> to continue after the import is complete at mult2.net. /*
In a different window, connect to the computer that runs the mult3.net database and import the export dump file hr_schema.dmp to instantiate the tables in the mult3.net database.
After you connect to mult3.net, perform the import in the same way that you did for mult2.net.
*/ PAUSE Press <RETURN> to continue after the import is complete at mult3.net. /*
Connect to mult2.net as the strmadmin user.
*/ CONNECT strmadmin/strmadminpw@mult2.net /*
Specify an update conflict handler for each table in the hr schema. For each table, designate the time column as the resolution column for a MAXIMUM conflict handler. When an update conflict occurs, such an update conflict handler applies the transaction with the latest (or greater) time and discards the transaction with the earlier (or lesser) time.
*/ DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'country_name'; cols(2) := 'region_id'; cols(3) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.countries', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; / DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'department_name'; cols(2) := 'manager_id'; cols(3) := 'location_id'; cols(4) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.departments', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; / DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'first_name'; cols(2) := 'last_name'; cols(3) := 'email'; cols(4) := 'phone_number'; cols(5) := 'hire_date'; cols(6) := 'job_id'; cols(7) := 'salary'; cols(8) := 'commission_pct'; cols(9) := 'manager_id'; cols(10) := 'department_id'; cols(11) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.employees', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; / DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'job_title'; cols(2) := 'min_salary'; cols(3) := 'max_salary'; cols(4) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.jobs', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; / DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'employee_id'; cols(2) := 'start_date'; cols(3) := 'end_date'; cols(4) := 'job_id'; cols(5) := 'department_id'; cols(6) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.job_history', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; / DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'street_address'; cols(2) := 'postal_code'; cols(3) := 'city'; cols(4) := 'state_province'; cols(5) := 'country_id'; cols(6) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.locations', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; / DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'region_name'; cols(2) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.regions', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; / /*
Set the disable_on_error parameter to n for both apply processes so that they will not be not disabled if they encounter an error, and start both of the apply processes at mult2.net.
*/ BEGIN DBMS_APPLY_ADM.SET_PARAMETER( apply_name => 'apply_from_mult1', parameter => 'disable_on_error', value => 'n'); END; / BEGIN DBMS_APPLY_ADM.START_APPLY( apply_name => 'apply_from_mult1'); END; / BEGIN DBMS_APPLY_ADM.SET_PARAMETER( apply_name => 'apply_from_mult3', parameter => 'disable_on_error', value => 'n'); END; / BEGIN DBMS_APPLY_ADM.START_APPLY( apply_name => 'apply_from_mult3'); END; / /*
Connect to mult3.net as the strmadmin user.
*/ CONNECT strmadmin/strmadminpw@mult3.net /*
Specify an update conflict handler for each table in the hr schema. For each table, designate the time column as the resolution column for a MAXIMUM conflict handler. When an update conflict occurs, such an update conflict handler applies the transaction with the latest (or greater) time and discards the transaction with the earlier (or lesser) time.
*/ DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'country_name'; cols(2) := 'region_id'; cols(3) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.countries', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; / DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'department_name'; cols(2) := 'manager_id'; cols(3) := 'location_id'; cols(4) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.departments', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; / DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'first_name'; cols(2) := 'last_name'; cols(3) := 'email'; cols(4) := 'phone_number'; cols(5) := 'hire_date'; cols(6) := 'job_id'; cols(7) := 'salary'; cols(8) := 'commission_pct'; cols(9) := 'manager_id'; cols(10) := 'department_id'; cols(11) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.employees', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; / DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'job_title'; cols(2) := 'min_salary'; cols(3) := 'max_salary'; cols(4) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.jobs', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; / DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'employee_id'; cols(2) := 'start_date'; cols(3) := 'end_date'; cols(4) := 'job_id'; cols(5) := 'department_id'; cols(6) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.job_history', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; / DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'street_address'; cols(2) := 'postal_code'; cols(3) := 'city'; cols(4) := 'state_province'; cols(5) := 'country_id'; cols(6) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.locations', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; / DECLARE cols DBMS_UTILITY.NAME_ARRAY; BEGIN cols(1) := 'region_name'; cols(2) := 'time'; DBMS_APPLY_ADM.SET_UPDATE_CONFLICT_HANDLER( object_name => 'hr.regions', method_name => 'MAXIMUM', resolution_column => 'time', column_list => cols); END; / /*
Set the disable_on_error parameter to n for both apply processes so that they will not be disabled if they encounter an error, and start both of the apply processes at mult3.net.
*/ BEGIN DBMS_APPLY_ADM.SET_PARAMETER( apply_name => 'apply_from_mult1', parameter => 'disable_on_error', value => 'n'); END; / BEGIN DBMS_APPLY_ADM.START_APPLY( apply_name => 'apply_from_mult1'); END; / BEGIN DBMS_APPLY_ADM.SET_PARAMETER( apply_name => 'apply_from_mult2', parameter => 'disable_on_error', value => 'n'); END; / BEGIN DBMS_APPLY_ADM.START_APPLY( apply_name => 'apply_from_mult2'); END; / /*
Connect to mult1.net as the strmadmin user.
*/ CONNECT strmadmin/strmadminpw@mult1.net /*
Set the disable_on_error parameter to n for both apply processes so that they will not be disabled if they encounter an error, and start both of the apply processes at mult1.net.
*/ BEGIN DBMS_APPLY_ADM.SET_PARAMETER( apply_name => 'apply_from_mult2', parameter => 'disable_on_error', value => 'n'); END; / BEGIN DBMS_APPLY_ADM.START_APPLY( apply_name => 'apply_from_mult2'); END; / BEGIN DBMS_APPLY_ADM.SET_PARAMETER( apply_name => 'apply_from_mult3', parameter => 'disable_on_error', value => 'n'); END; / BEGIN DBMS_APPLY_ADM.START_APPLY( apply_name => 'apply_from_mult3'); END; / /*
Start the capture process at mult1.net.
*/ BEGIN DBMS_CAPTURE_ADM.START_CAPTURE( capture_name => 'capture_hr'); END; / /*
Connect to mult2.net as the strmadmin user.
*/ CONNECT strmadmin/strmadminpw@mult2.net /*
Start the capture process at mult2.net.
*/ BEGIN DBMS_CAPTURE_ADM.START_CAPTURE( capture_name => 'capture_hr'); END; / /*
Connect to mult3.net as the strmadmin user.
*/ CONNECT strmadmin/strmadminpw@mult3.net /*
Start the capture process at mult3.net.
*/ BEGIN DBMS_CAPTURE_ADM.START_CAPTURE( capture_name => 'capture_hr'); END; / SET ECHO OFF /*
Check the streams_mult.out spool file to ensure that all actions finished successfully after this script is completed.
*/ SET ECHO OFF SPOOL OFF /*************************** END OF SCRIPT ******************************/
You can make DML and DDL changes to the tables in the hr schema at any of the databases in the environment. These changes will be replicated to the other databases in the environment, and you can run queries to view the replicated data.
For example, complete the following steps to make DML changes to the hr.employees table at mult1.net and mult2.net. To see the update conflict handler you configured earlier resolve an update conflict, you can make a change to the same row in these two databases and commit the changes at nearly the same time. Then, you can query the hr.employees table at each database in the environment to confirm that the changes were captured, propagated, and applied correctly.
You can also make a DDL change to the hr.jobs table at mult3.net and then confirm that the change was captured at mult3.net, propagated to the other databases in the environment, and applied at these databases.
Make the following changes. Try to commit them at nearly the same time, but commit the change at mult2.net after you commit the change at mult1.net.
CONNECT hr/hr@mult1.net UPDATE hr.employees SET salary=9000 WHERE employee_id=206; COMMIT; CONNECT hr/hr@mult2.net UPDATE hr.employees SET salary=10000 WHERE employee_id=206; COMMIT;
Alter the hr.jobs table by renaming the job_title column to job_name:
CONNECT hr/hr@mult3.net ALTER TABLE hr.jobs RENAME COLUMN job_title TO job_name;
After some time passes to allow for capture, propagation, and apply of the changes performed in Step 1, run the following query to confirm that the UPDATE changes have been applied at each database.
CONNECT hr/hr@mult1.net
SELECT salary FROM hr.employees WHERE employee_id=206;
CONNECT hr/hr@mult2.net
SELECT salary FROM hr.employees WHERE employee_id=206;
CONNECT hr/hr@mult3.net
SELECT salary FROM hr.employees WHERE employee_id=206;
All of the queries should show 10000 for the value of the salary.
After some time passes to allow for capture, propagation, and apply of the change performed in Step 2, describe the hr.jobs table at each database to confirm that the ALTER TABLE change was propagated and applied correctly.
CONNECT hr/hr@mult1.net
DESC hr.jobs
CONNECT hr/hr@mult2.net
DESC hr.jobs
CONNECT hr/hr@mult3.net
DESC hr.jobs
Each database should show job_name as the second column in the table.
|
 Copyright © 2002 Oracle Corporation. All Rights Reserved. |
|

