Release 2 (9.2)
Part Number A96597-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Real Application Clusters Concepts Release 2 (9.2) Part Number A96597-01 |
|
This chapter describes Cache Fusion processing and explains Global Cache Service (GCS) operations. It also explains the resource control mechanisms in Real Application Clusters, illustrates common Cache Fusion scenarios, and describes recovery processing in Real Application Clusters. The topics in this chapter include:
By default, a resource is allocated for each data block that resides in the cache of an instance. Due to Cache Fusion and the elimination of disk writes that occur when other instances request blocks for modifications, the performance overhead to manage shared data between instances is greatly diminished. Not only do Cache Fusion's concurrency controls greatly improve performance, but they also reduce the administrative effort for Real Application Clusters environments.
Cache Fusion addresses several types of concurrency as described under the following headings:
Concurrent reads on multiple nodes occur when two instances need to read the same data block. Real Application Clusters resolves this situation without synchronization because multiple instances can share data blocks for read access without cache coherency conflicts.
A read request from an instance for a block that was modified by another instance and not yet written to disk can be a request for either the current version of the block or for a read-consistent version. In either case, the Global Cache Service Processes (LMSn) transfer the block from the holding instance's cache to the requesting instance's cache over the interconnect.
Concurrent writes on different nodes occur when the same data block is modified frequently by different instances. In such cases, the holding instance completes its work on the data block after receiving a request for the block. The GCS then converts the resources on the block to be globally managed and the LMSn processes transfer a copy of the block to the cache of the requesting instance. The main features of this processing are:
When an instance requests a block for modification, the Global Cache Service Processes (LMSn) send the block from the instance that last modified it to the requesting instance. In addition, the LMSn process retains a PI of the block in the instance that originally held it.
Writes to disks are only triggered by cache replacements and during checkpoints. For example, consider a situation where an instance initiates a write of a data block and the block's resource has a global role. However, the instance only has the PI of the block and not the most current buffer. Under these circumstances, the instance informs the GCS and the GCS forwards the write request to the instance where the most recent version of the block is held. The holder then sends a completion message to the GCS. Finally, all other instances with PIs of the block delete them.
The GCS assigns and opens resources for each data block read into an instance's buffer cache. Oracle closes resources when the resources do not manage any more buffers or when buffered blocks are written to disk due to cache replacement. When Oracle closes a resource, it returns the resource to a list from which Oracle can assign new resources.
An additional concurrency control concept is the buffer state which is the state of a buffer in the local cache of an instance. The buffer state of a block relates to the access mode of the block. For example, if a buffer state is exclusive current (XCUR), an instance owns the resource in exclusive mode.
To see a buffer's state, query the STATUS column of the V$BH dynamic performance view. The V$BH view provides information about the block access mode and their buffer state names as follows:
NULL the buffer state name is CR--An instance can perform a consistent read of the block. That is, if the instance holds an older version of the data.S the buffer state name is SCUR--An instance has shared access to the block and can only perform reads.X the buffer state name is XCUR--An instance has exclusive access to the block and can modify it.NULL the buffer state name is PI--An instance has made changes to the block but retains copies of it as past images to record its state before changes.Only the SCUR and PI buffer states are Real Application Clusters-specific. There can be only one copy of any one block buffered in the XCUR state in the cluster database at any time. To perform modifications on a block, a process must assign an XCUR buffer state to the buffer containing the data block.
For example, if another instance requests read access to the most current version of the same block, then Oracle changes the access mode from exclusive to shared, sends a current read version of the block to the requesting instance, and keeps a PI buffer if the buffer contained a dirty block.
At this point, the first instance has the current block and the requesting instance also has the current block in shared mode. Therefore, the role of the resource becomes global. There can be multiple shared current (SCUR) versions of this block cached throughout the cluster database at any time.
The following scenarios illustrate the most important points of Cache Fusion processing. These scenarios do not address all possible configurations. For example, this section does not describe read operations. The scenarios in this section are:
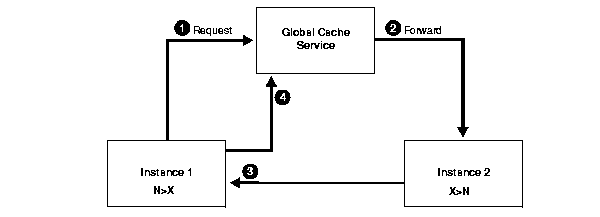
The scenario in Figure 6-1 assumes that the data block has been changed, or dirtied, by only one instance and held in exclusive mode (X). Furthermore, this scenario assumes that the block has only been accessed by the instance that changed it. That is, only one copy of it exists cluster-wide. In other words, the block has a local role (L).
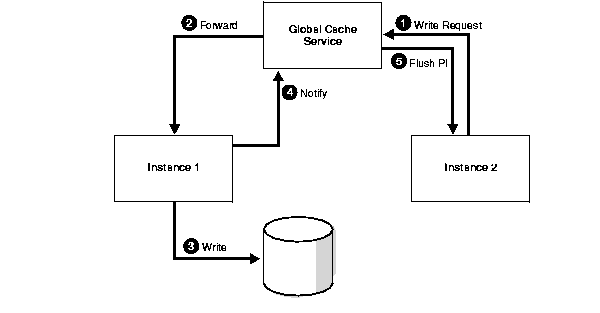
The scenario in Figure 6-2 illustrates how an instance can perform a checkpoint at any time or replace buffers in the cache due to free buffer requests. Because multiple versions of the data block with changes could exist in the caches of instances in the cluster, a write protocol managed by the GCS ensures that only the most current version of the data is written to disk. It must also ensure that all previous versions are purged from the other caches. A write request for a data block can originate in any instance that has the current or past image of the block.
In this scenario, assume that the instance holding a PI buffer in null mode requests that Oracle write the buffer to disk.
The next section explains Real Application Clusters recovery.
In Real Application Clusters recovery, the amount of recovery processing required after node failures is proportional to the number of failed nodes. In general, data blocks become available immediately after they are recovered.
When an instance fails and the failure is detected by another Oracle instance, Oracle performs the following recovery steps:
In summary, the recovered database or recovered portions of the database become available earlier, and before the completion of the entire recovery sequence. This makes the system available sooner and it makes recovery more scalable.
If neither the PI buffers nor the current buffer for a data block are in any of the surviving instances' caches, then Oracle performs a log merge of the failed instances. As mentioned for recovery in general, the performance overhead of a log merge is proportional to the number of failed instances and to the size of the redo logs for each instance. You can, however, control the size of the log with Oracle's checkpoint features. With its advanced design, Real Application Clusters recovery can manage multiple simultaneous failures and sequential failures. The shared server feature is also resilient to instance failures during recovery.
| See Also:
Oracle9i Real Application Clusters Administration for more information about recovery in Real Application Clusters |
Chapter 7 describes the resource coordination performed by the Global Enqueue Service.
|
 Copyright © 1998, 2002 Oracle Corporation. All Rights Reserved. |
|

